内存管理始终是底层软件的核心部分,尤其是对于音视频的解码显示功能。本文将通过编写一个实例驱动程序,同内核中的i915显卡驱动进行内存方面的交互来剖析 Linux内核中的通用子系统DMA_BUF。
DMA_BUF
需求背景
考虑这样一种场景,摄像头采集的视频数据需要送到GPU中进行编码、显示。负责数据采集和编码的模块是Linux下不同的驱动设备,将采集设备中的数据送到编码设备中 需要一种方法。最简单的方法可能就是进行一次内存拷贝,但是我们这里需要寻求一种免拷贝的通用方法。
实际的硬件环境是,采集设备是一个pciv驱动,编码设备就是i915驱动。现在就是要编写一个驱动程序,让i915驱动可以直接访问pciv中管理的视频数据内存。
概述
引入dma-buf机制的原因
-
之前内核中缺少一个可以让不同设备、子系统之间进行内存共享的统一机制。
-
混乱的共享方法:
-
V4L2(video for Linux)使用
USERPTR的机制来处理访问来自其他设备内存的问题,这个机制需要借助于以后空间的mmap方法。 -
类似的,wayland和x11各自定义了客户端和主进程之间的内存共享机制,而且都没有实现不同设备间内存共享的机制。
-
内核中各种soc厂商的驱动、各种框架和子系统都各自实现各自的内存共享机制。
-
-
之前共享方式存在问题:
-
使用用户层的mmap机制实现内存共享方式太过简单粗暴,难以移植。
-
没有统一的内存共享的API接口。
-
dma_buf是一种怎样的存在
dma_buf是内核中一个独立的子系统,提供了一个让不同设备、子系统之间进行共享缓存的统一框架,这里说的缓存通常是指通过DMA方式访问的和硬件交互的内存。 比如,来自摄像头采集的通过pciv驱动传输的内存、gpu内部管理的内存等等。
其实一开始,dma_buf机制在内核中的主要运用场景是支持GPU驱动中的prime机制,但是作为内核中的通用模块,它的适用范围很广。
dma_buf子系统包含三个主要组成:
-
dma-buf对象,它代表的后端是一个sg_table,它暴露给应用层的接口是一个文件描述符,通过传递描述符达到了交互访问dma-buf对象,进而最终达成了 共享访问sg_table的目的。
-
fence对象, which provides a mechanism to signal when one device as finished access.
-
reservation对象, 它负责管理缓存的分享和互斥访问。.
dma-buf实现
整体构架
DMA_BUF框架下主要有两个角色对象,一个是exporter,相当于是buffer的生产者,相对应的是importer或者是user,即buffer的消费使用者。
假设驱动A想使用由驱动B产生的内存,那么我们称B为exporter,A为importer.
The exporter
-
实现struct dma_buf_ops中的buffer管理回调函数。
-
允许其他使用者通过dma_buf的sharing APIS来共享buffer。
-
通过struct dma_buf结构体管理buffer的分配、包装等细节工作。
-
决策buffer的实际后端内存的来源。
-
管理好scatterlist的迁移工作。
The buffer-usr
-
是共享buffer的使用者之一。
-
无需关心所用buffer是哪里以及如何产生的。
-
通过struct dma_buf_attachment结构体访问用于构建buffer的scatterlist,并且提供将buffer映射到自己地址空间的机制。
数据结构
struct dma_buf{
size_t size;
struct file *file; /* file pointer used for sharing buffers across,and for refcounting */
struct list_head attachments; /* list of dma_buf_attachment that denotes all devices attached */
const struct dma_buf_ops *ops;
struct mutex lock;
unsigned vmapping_counter;
void *vmap_ptr;
const char *exp_name; /* name of the exporter; useful for debugging */
struct module *owner;
struct list_head list_node; /* node for dma_buf accounting and debugging */
void *priv; /* exporter specific private data for this buffer object */
struct reservation_object *resv; /* reservation object linked to this dma-buf */
wait_queue_head_t poll;
struct dma_buf_poll_cb_t{
struct fence_cb cb;
wait_queue_head_t *poll;
unsigned long active;
}cb_excl, cb_shared;
};
dma_buf对象中最重要的成员变量是ops方法集,dma_buf本身是一个通用的框架,正是依靠这里的ops回调函数集来实现dma_buf对象的重载功能,所谓重载就是
说dma_buf框架可以用于不同的运用场景。所以ops定义的回调函数是我们编写dma_buf框架下exporter驱动的主要实现代码。
ops中定义的回调函数都对应着dma_buf模块外部头文件dma_buf.h中的API,比如其他驱动调用dma_buf.h中的dma_buf_attach()API时,实际最终调用的就是
我们实现的ops中的int (*attach)(struct dma_buf *, struct device *, struct dma_buf_attachment *)方法;调用dma_buf_map_attachment() API
实际就是调用ops中的struct sg_table * (*map_dma_buf)(struct dma_buf_attachment *, enmu dma_data_direction)方法。
dma_buf对象中更加重要的一个成员变量是file,我们知道一切皆文件是unix的核心思想。dma_buf子系统之所以可以使不同的驱动设备可以共享访问内存,就
是借助于文件系统是全局的这个特征。另外,因为Unix操作系统都是通过Unix domain域的socket使用SCM_RIGHTS语义来实现文件描述符传递,所以安全性很高。和dma_buf对象中file成员变量对应的API接口有,dma_buf_export()、dma_buf_fd()。
/**
* dma_buf_export - Create a new dma_buf, and associates an anon file with this buffer,
* so it can be exported.
*/
struct dma_buf *dma_buf_export(const struct dma_buf_export_info *exp_info)
{
struct dma_buf *dma_buf;
struct file *file;
...
dmabuf = kzalloc(alloc_size, GFP_KERNEL);
if(!dmabuf){
module_put(exp_info->owner);
return ERR_PTR(-ENOMEM);
}
...
dmabuf->ops = exp_info->ops; //[0]
...
file = anon_inode_getfile("dmabuf", &dma_buf_fops, dmabuf, exp_info->flags); //[1]
file->f_mode |= FMODE_LSEEK;
dmabuf->file = file;
...
return dmabuf;
}
上面[0]出传入的ops方法集就是上面提到的我们编写驱动应该实现的回调函数集,dmabuf通过anon_inode_getfile()函数挂载到了file对象上的
priv指针上,而dma_buf_fops回调函数集挂载在file对象上的ops上,最后dma_buf_fops函数集中的回调函数实现都会通过file->priv拿到dma_buf对象,
然后直接调用dma_buf中的ops方法。这样的函数重载实现是file作为驱动程序接口功能实现的常规操作.
dma_buf_fd()函数的实现很简单,就是根据传入的dma_buf对象,生成全局可见的文件描述符fd。后面正是通过这个fd作为媒介来实现各个驱动设备间的 交互。
运作流程
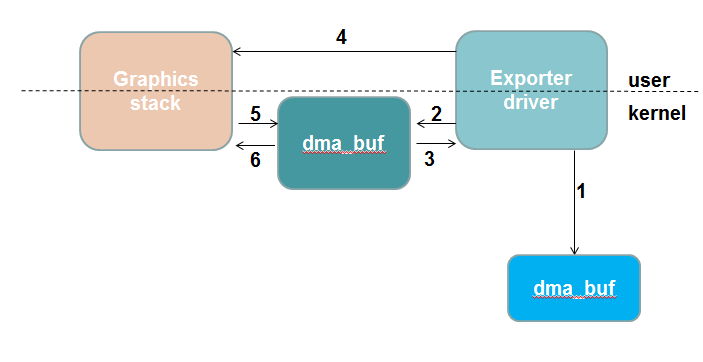
-
Exporter驱动申请或者引用导入的待共享访问的内存。
-
Exporter驱动调用dma_buf_export()创建dma_buf对象,同时将自定义的struct dma_buf_ops方法集和步骤1中的内存挂载到dma_buf对象中。
-
Exporter驱动调用dma_buf_fd()将步骤2中创建的dam_buf对象关联到全局可见的文件描述符fd,同时通过ioctl方法将fd传递给应用层。
-
应用层将fd传递给importer驱动程序。
-
importer驱动通过调用dma_buf_get(fd)获取dma_buf对象。
-
importer驱动调用dma_buf_attach()和dma_buf_map_attachment()获取共享缓存的信息。
Importer驱动实例剖析
Linux内核中的DRM子系统中实现了importer功能,这样我们可以通过实现exporter驱动来将某个内存传递进DRM子系统中,让DRM进行访问。
上面描述的运作流程中的4~6步骤都是importer需要实现的代码,其中对应于第4点,drm驱动中通过ioctl的DRM_IOCTL_PRIME_FD_TO_HANDLE命令来将应用层
传递的fd转换为对应的dma_buf对象。不过要注意的是,drm中对应这个命令的函数不仅是将fd转换为了dma_buf对象,同时还将这个dma_buf对象通过idr机制将dmd_buf
索引为handle,方便drm驱动中进行内存的管理。具体函数实现如下:
int drm_gem_prime_fd_to_handle(struct drm_device *dev, struct drm_file *file_priv, int prime_fd, uint32_t *handle)
{
struct dma_buf *dma_buf;
struct drm_gem_object *obj;
int ret;
dma_buf = dma_buf_get(prime_fd); //[0]
...
ret = drm_prime_lookup_buf_handle(&file_priv->prime, dma_buf, handle); //[1]
if(ret == 0)
{
...
return 0;
}
...
obj = dev->driver->gem_prime_import(dev, dma_buf); //[2]
...
drm_gem_handle_create_tail(file_priv, obj, handle); //[3]
...
drm_prime_add_buf_handle(&file_priv->prime, dma_buf, *handle); //[4]
...
dma_buf_put(dma_buf); //[5]
return 0;
}
上面代码中的[0]处就是实现了运作流程中的第5点。
从drm_gem_prime_fd_to_handle()函数的实现的[1]处可见,当prime_fd对应的内存对象已经通过dma_buf机制获取过,那么prime的机制和drm中的flink机制 一样,用于将bo在多个上下文下共享。也就是说上面代码中的[1]、[3]、[4]处和dma_buf机制没有关系,而是drm中的bo对象管理机制,基于的是idr机制。所以下面 重点分析[1]处的代码实现,其回调实现如下:
struct drm_gem_object *i915_gem_prime_import(struct drm_device *dev, struct dma_buf *dma_buf)
{
struct dma_buf_attachment *attach;
struct drm_gem_object *obj;
...
attach = dma_buf_attach(dma_buf, dev->dev); //[0]
get_dma_buf(dma_buf);
obj = i915_gem_object_alloc(dev); //[1]
...
drm_gem_private_object_init(dev, &obj->base, dma_buf->size);
i915_gem_object_init(obj, &i915_gem_object_dmabuf_ops); //[2]
obj->base.import_attach = attach;
return &obj->base;
}
从上面代码看,i915_gem_prime_import()貌似只是完成了运作流程步骤中第6点的一半工作,即[0]处调用的dma_buf_attach(),并没有调用 dma_buf_map_attachment()方法。其实i915驱动是将dma_buf_map_attachment()函数的调用lazy到了obj->ops中去了,即上面代码中[2]处 注册的方法集i915_gem_object_dmabuf_ops。i915驱动中调用obj->ops中方法的流程如下:
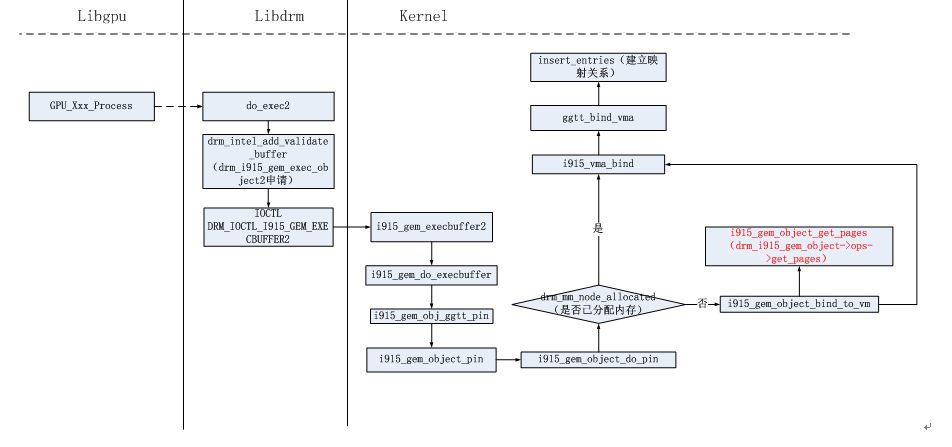
通过上面的具体流程可以看出,当i915驱动需要实际使用内存时,会调用obj->pos中的get_pages()方法。而这个方法的具体实现如下:
static int i915_gem_object_get_pages_dmabuf(struct drm_i915_gem_object *obj)
{
struct sg_table *sg;
sg = dma_buf_map_attachment(obj->base.import_attach, DMA_BIDIRECTIONAL);
...
obj->pages = sg;
return 0;
}
static void i915_gem_object_put_pages_dmabuf(struct drm_i915_gem_object *obj)
{
dma_buf_unmap_attachment(obj->base.import_attach, obj->pages, DMA_BIDIRECTIONAL);
}
static const struct drm_i915_gem_object_ops i915_gem_object_dmabuf_ops = {
.get_pages = i915_gem_object_get_pages_dmabuf,
.put_pages = i915_gem_object_put_pages_dmabuf,
};
至此,作为linux内核中一个dma_buf的importer实例,即i915驱动中的importer运作流程分析完成了。