做音视频中间件开发的,不可避免的会遇到各种性能问题。不同于一般的bug,性能问题往往比较隐蔽,如果不借助于工具,只能是通过代码逻辑去揣测、去 猜想问题的原因,然后就是无休止的尝试。除了解决已经遇到到的性能问题,我们在设计实现新架构代码时,或者是去优化重构别人代码时,我们怎样去证明我们 的架构、我们的优化时合理高效的。所以掌握软件性能分析的技术和工具使用是称为高水平程序员的必备条件,更应该是称为架构师的前提条件。
Perf 简介
Perf,最初的时候叫Performance counter,在2.6.31中首次出现,在2.6.32后正式更名为Performance Event。它是集成与内核代码中的进行软件性能分析的 工具。
通过它,应用程序可以使用PMU,tracepoint和内核中的特殊计数器进行性能统计。Perf不仅可以分析指定应用程序的性能问题,也可以用来定位内核性能问题,当然也 可以同时分析应用代码和内核,从而全面了解应用程序中的性能瓶颈。
使用Perf,你可以分析程序运行期间发生的硬件事件,比如instructions retired, processor clock cycles等;你也可以分析软件事件,比如Page Fault和进程切换。
这使得Perf拥有了众多的性能分析能力,举例来说,使用Perf可以计算每个时钟周期内的指令数IPC(instruction per cycles),IPc偏低表明代码没有 很好利用CPU。Perf还可以对程序进行函数级别的采样,从而了解程序的性能瓶颈究竟在哪里等等。
Perf还可以替代strace,并且性能比strace提升几十倍,可以动态添加内核probe点,还可以做benchmark衡量调度器的好坏。
perf的编译安装、环境部署
背景知识与基础
不同于gdb这样的调试工具,如果你不掌握足够软件性能相关的基础背景知识,即使你熟悉每一个perf工具的命令,你依然发挥不了perf的作用。
性能相关的处理器硬件特性
cache
内存读写是很快的,但还是无法和处理器的指令执行速度相比。为了从内存中读取指令和数据,处理器需要等待,用处理器的时间来衡量,这种等待很漫长。 cache的读写速度非常快,能和处理器速度匹配。因此将常用的数据保存在cache中,处理器便无须等待,从而提高性能。但是,cache的容量一般很小,充分 利用cache是软件调优非常重要的部分。这里说的硬件cache和linux内核中实现的cache机制是不同的,不能混淆。关于linux下的buffer/cache知识,见这篇文章.
pipeline
提高性能最有效的方式之一就是并行。因此现代的处理器在硬件设计上都提供流水线(pipeline)技术来尽可能保证真正的指令并行。
处理器处理一条指令需要分多个步骤完成,比如先取指令,然后完成运算,最后将计算结果写回。在处理器内部,这就可以看作是一个三级流水线。 不同架构的处理器支持不同级数的流水线,比如arm9就支持了6级流水线,而intel架构的cpu一般支持三级流水线。流水线越多,表明一个时钟周期可以 同时处理的指令数越多。
大多数的pipeline主要由两部分组成,前端(front-end)和后端(back-end)。在x86架构的处理器中,pipeline的front-end负责从内存中获取指令,并将有序的汇编指令解码成机器原语(micro-operations);back-end负责执行这些micro-operations。关于pipeline的front-end和back-end的详细内容可参见intel工程师的两篇 博文front-end、back-end。下面引用其中核心的描述:
So for X86-based processors, the front-end does two main things - fetch instructions(from where program binaries are stored in memory or the caching system), and decode them into micro-operations.As part of the fetching process, the front-end must also predict the targets of branch instructions when they are encountered, so that it knows where to grab the next instructions from.
perf工具的stat命令结果中的stalled-cycles-frontend和stalled-cycles-backend就是统计了pipeline的这两部分的工作状态。
上述的文章中提到了,在处理器内部,不同指令所需要的处理器步骤和时钟周期是不同的,如果严格按照程序的执行顺序执行,那么就无法充分利用处理器的流水线。因此指令有可能被乱序执行。
上述并行技术对所执行的指令有一个基本要求,即相邻的指令没有依赖关系。假如某条指令需要依赖前面的一条指令的执行结果数据,那么这些技术就 无法被利用。因此,在使用perf工具的stat命令时,有一个非常重要的统计指标就是IPC(instructions per cycle),一般这个值大于1.0时,才表示程序 的执行效率是健康的。大神Brendan Gregg关于IPC的解释如下:
IPC is a commonly examined metric, either IPC or its invert, CPI. Higher IPC values mean higher instrucion throughput, and lower values indicated more stall cycles. I’d generally interpert high IPC values(eg, over 1.0) as good, indicating optimal processing of work. However, I’d want to double check what the instructions are, in case this is due to s spin loop: a high rate of instructions, but a low rate of actual work completed.
分支预测
分支指令对软件性能有比较大的影响。尤其是当处理器采用流水线设计之后,假设流水线有三级,当前进入流水的第一条指令为分支指令。假设处理器顺序读取指令,那么如果分支的结果是跳转到其他指令,那么被处理器流水线预取的后续两条指令都将被放弃,从而影响性能。为此,很多处理器都提高分支预测功能,根据一条指令的历史执行记录进行预测,读取最可能的下一条指令,而非顺序读取指令。
分支预测对软件结构有一些要求,对于重复性的分支指令序列,分支预测硬件得到较好的预测结果,而对于类似switch case一类的程序结构,则往往无法得到理想的预测结果。关于linux中分支预测的运用请看这篇文章中的相关章节。
PMU
上面介绍的几种处理器硬件特性对软件的性能有很大的影响,然而依赖时钟进行定期采样的profiler模式无法揭示程序对这些处理器硬件特性的真实使用情况。 处理器厂商针对这种情况,在硬件中加入了PMU(performace monitor unit)单元。
PMU允许软件针对某种硬件事件设置counter,此后处理器便开始统计该事件的发生次数,当发生的次数超过counter内设置的值后,便产生中断。比如cashe miss达到 某个值后,PMU便能产生相应的中断。捕获这些中断,便可以考察程序对这些硬件特性的利用效率了。
perf实战
Dynamic Tracing
内核代码的调试不像应用程序那么方便,大部分情况下我们只是通过在内核代码中添加打印来调试,效率非常的低下。部署使用KGDB也比较麻烦,本节介绍如何使用内核 自带的调试工具perf中的probe命令,实现部分动态追踪调试的功能。
在嵌入式环境下使用起来probe的动态追踪功能需要克服一些困难,有些困难在网上可以找到解决方法,但是有些困难因为开发环境的差异,只能自己啃源码才能找到解决办法。为了分享自己解决问题的方法给其他人,介绍自己的开发环境是非常重要的一步。
- 内核版本 4.4.77
- 编译环境 centos 编译服务器
- 执行环境 intel x86_64 i7
可以看出,我的开发环境属于嵌入式交叉编译运行环境,工具的部署比较麻烦一点。
内核代码的追踪
我们这里介绍的Dynamic Tracing方法主要是参考大神Brendan Gregg的文章perf example里面的6.6节。关于内核的支持情况,里面只是简单的提到设置一些宏开关,怎么去开启这些宏没有说明。本文下面叙述的配置方法是基于linux 4.4.77内核的。
为了可以执行perf probe --add snd_pcm_period_elapsed命令在内核中任意函数设置event,CONFIG_KPROBES=y 和 CONFIG_KPROBE_EVENTS=y这两个宏必须被设置。
执行make menuconfig,在如下路径开启选项:
kernel hacking
--> Tracers
--> Enable kprobes-based dynamic events
关于设置event的概念,其实就可以简单的理解为和gdb中设置断点差不多,为了获取event被触发时的调用堆栈,需要设置CONFIG_FRAME_POINTER=y,开启路径如下:
kernel hacking
--> Compile-time checks and compiler options
--> Compile the kernel with frame pointers
这样配置好内核后,从新编译加载内核,执行perf probe --add snd_pcm_period_elapsed结果如下:
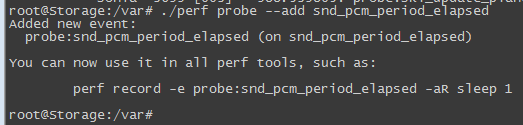
上面提示我们可以执行perf record -e probe:xxx命令来检测刚才上面设置的event, 执行结果如下:
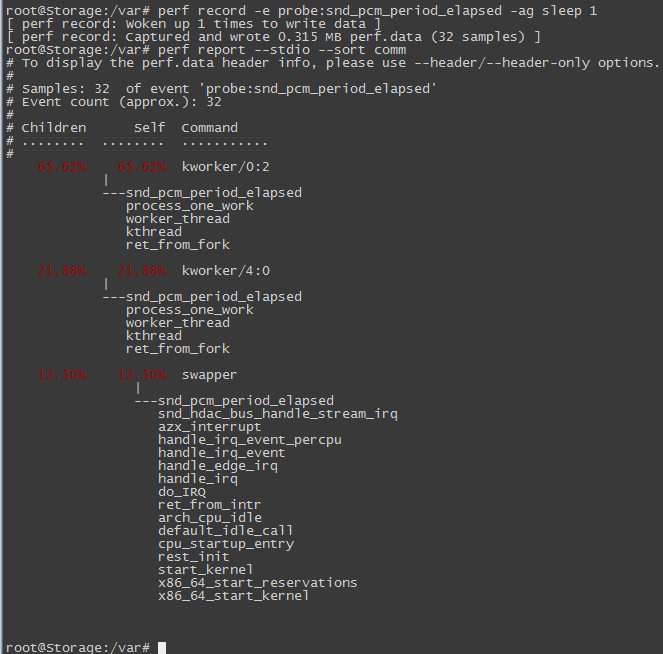
是不是很爽,这样我们就实现了gdb断点之后执行bt查看堆栈的功能,这个功能对于我们研究内核代码有非常大的帮助。和gdb断点一样,我们不仅可以将event
设置成函数名,也可以设置到函数中的任意一行,perf probe --add snd_pcm_period_elapsed:128,语法和gdb一样。
下面来一点更爽的事情,上面我们只是看到调用堆栈,很多时候,我们希望看到函数内部操作的局部变量和全局变量,执行perf probe -V可以查看哪些变量
可以被监测,为了实现这个功能,需要CONFIG_DEBUG_INFO=y被设置,并且好像加载内核的debuginfo,以及设置好debuginfo文件的路径。
内核代码中一部分函数符号信息是解析到/proc/kallsyms文件中的,上面执行的probe –add就是去解析这个文件中的符号的。 但是/proc/kallsyms中一般没有变量的符号信息,所以需要我们自己加载这些信息。
设置CONFIG_DEBUG_INFO=y后,执行编译内核,会在跟目录下生成包含完整的内核调试信息的vmlinux文件,这个就是所谓的内核的debuginfo。设置宏的路径如下:
kernel hacking
--> Compile-time checks and compiler options
--> Compile the kernel with debug info
保存配置,从新编译内核,加载vmlinux和bzImage,下面要做的是设置debuginfo的路径,好让perf去找到符号信息。这个过程被自己坑了一把。我们先来看看 没有正确添加debuginfo时的错误提示:

上面我已经通过-k /var/vmlinux选择正确设置了内核debuginfo的查找路径,但是任然提示找不到,加上-v选项后,多了个提示打印,说明设置的
路径是被识别的,可为什么还是不行呢?网上苦苦找寻相关问题,发现没有任何有价值的信息,没办法,只能使出绝招了,gdb跟踪perf源码。源码在手,天下
我有。
根据错误打印,确定perf中加载debuginfo的函数堆栈如下:
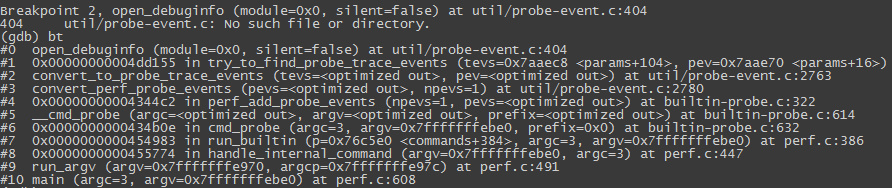
单步跟踪进去,最终在下面代码段锁定了问题:
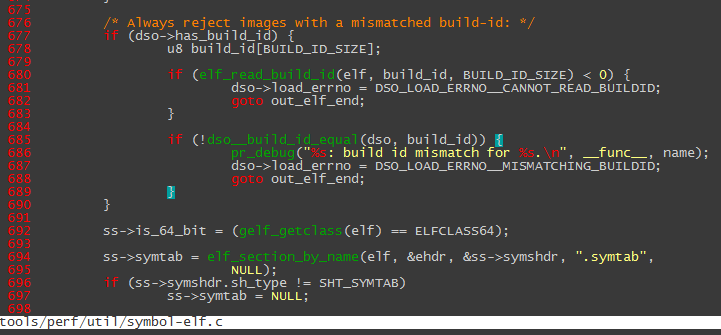
原来是bzImage的build id 和 vmlinux 的build id 不一致导致的,因为我中间操作的问题,导致这两个文件不是同一次编译出来的。
问题解决后,执行命令如下:
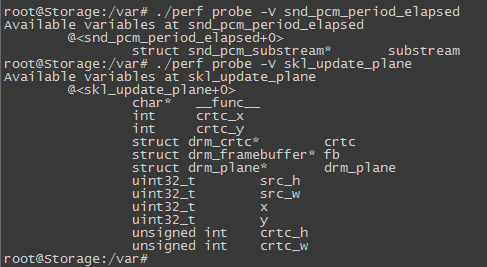
因为snd_pcm_period_elapsed函数是alsa驱动中的核心中断处理函数,调用太频繁,下面我们换用,显示驱动中的函数skl_update_plane,这个函数 是用来更新显示控制器的寄存器值的,只在显示接口进行插拔时才会调用。
下面,我们来打印其中的最后两个入参,src_w 和src_h:
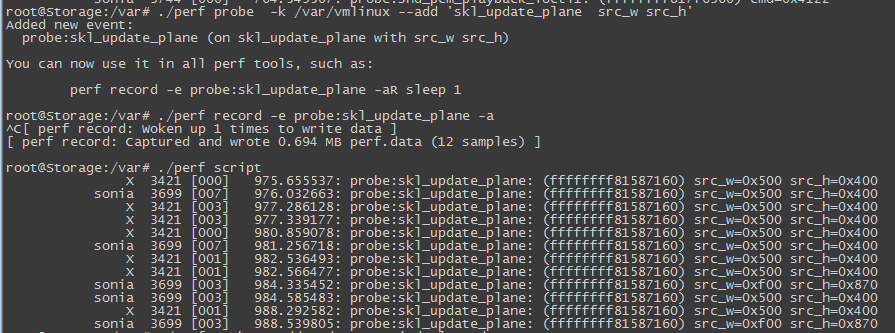
这样我们动态追踪内核代码的功能就实现了。
用户层代码追踪
Perf Top命令
perf top命令和linux下的top命令有点相似,实时打印出系统中被采样事件的状态和统计数据。perf top主要用于实时剖析各个函数在某个性能 事件(event)上的热度,默认的event是cycles(cpu周期数),这样可以检测系统中所有应用层和内核层函数的热度。
perf top支持两种输出界面,tui和tty,默认是tui,因为tui需要更多的环境和库支持,所以经常出现乱码问题,所以本文都是基于tty界面分析(–stdio)。
直接执行perf top监控的是整个系统中所有进程的状态,多数情况我们只关心某个进程,或者想定位某个线程的性能问题,perf top都是支持的(-p / -t)。
比如,我现在想查看一下项目中解码线程的热度状态,执行perf top -t 5449 --stdio,输出结果如下:
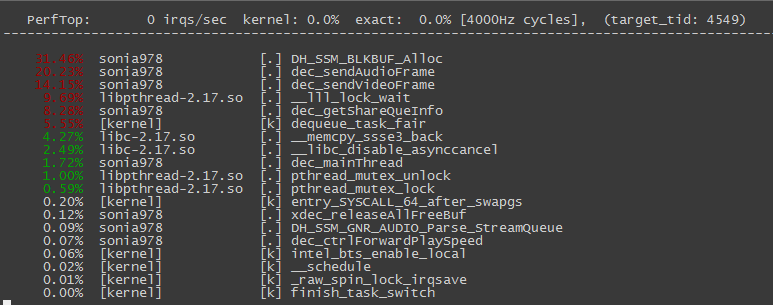
如上图,top工具输出界面有4列信息。最右边一列是符号名,即函数名。左边第一列为该符号引发的性能事件在整个检测域中占的比例,也就是我们所说的 热度。第二列为该符号所在的动态共享对象DSO(Dynamic Shared Object)的缩写。第三列为DSO的类型,perf中DSO共有5中类型,分别是:ELF可执行文件([.]) ,动态链接库([.]),内核([k]),VDSO等。
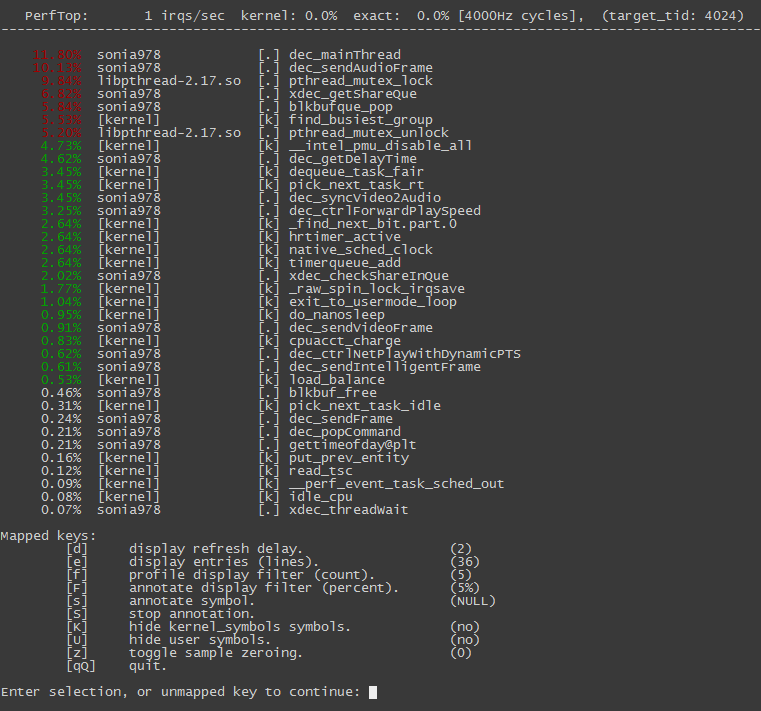
按下Enter键可以弹出热键菜单,其中比较重要的是其中的[s]和[S],分别是查看注解(annotate)和关闭注解功能。注解功能就是进一步深入分析某个热点 函数内部具体热点代码段,比如上图结果显示,整个线程20.23%的运行时间都消耗在dec_sendAudioFrame函数里面,但是我们希望知道这个函数里面具体 哪段代码导致这样的热度。使用annotate功能,可以得到答案,但是我的系统环境下,annotate功能不能正常工作,原因待查。
除了需要进入函数内部一探究竟,有时对于像上面的DH_SSM_BLKBUF_ALLOC这样的函数的调用堆栈,以定位到是哪里在频繁调用。这时候可以执行
perf top -t 4010 --stdio -g -K,结果如下:
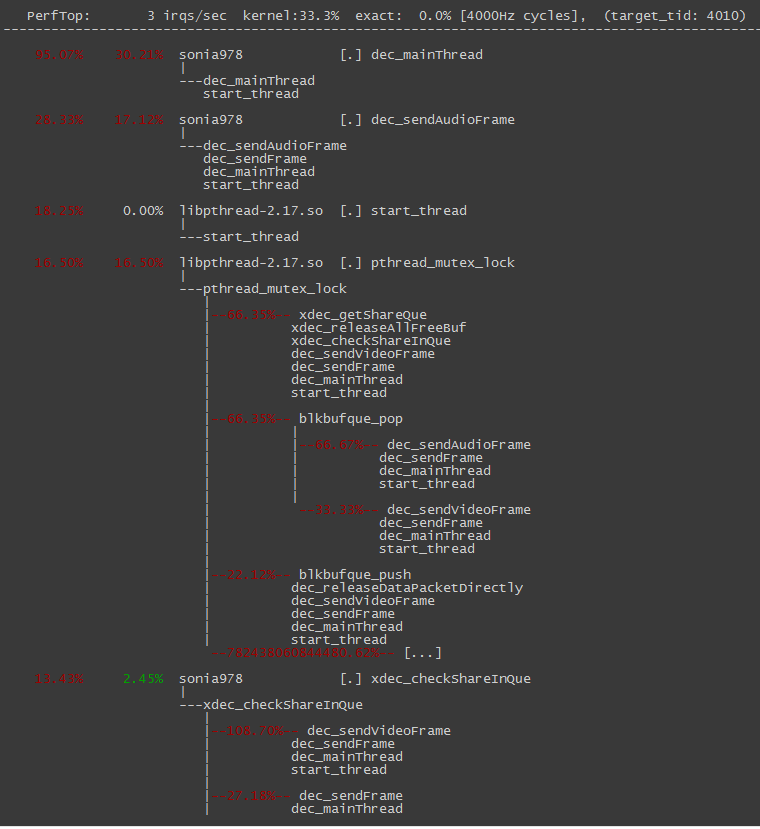
上面的-g参数就是现实函数的调用堆栈,-k是为了只输出应用层函数,和在按下Enter后再按热键[k]效果一样。
perf record/report
tips
-
record添加
-g选项后,report结果中默认只有热度打于%0.5的函数才会有详细堆栈信息,为了减小这个threshold,可以执行perf report -g graph,0.3 -
report输出中第一列的比例(children)是当前符号调用所有其他符号占用之和;第二列(self)是自身占用比例。