多年的实际工作经历表明,相比于设计和实现代码,调试代码的时间占工作时间的大部分。
《The Art of Unix Programming》中有这么一段话,c和c++的中心问题在于它们要求程序员自己完成内存管理--声明变量、显式管理链表、设置缓冲大小、检测或者防止缓冲区溢出,以及分配和回收动态存储。c的内存管理是复杂性和错误的渊源。对于处理复杂数据结构的程序而已,有研究估计30%~40%的开发时间都用于存储管理。这个估计甚至还没有包含对调试成本的影响。
所以现在工作中经常出现的情况时,一个bug花了几天甚至一周的时间进行定位,最终通过修改几行甚至是一行代码解决了问题。基于这些事实,提高自己的调试技术水平对于工作效率是至关重要的。工欲善其事必先利其器,掌握各种调试工具是立足之本,而自制调试工具往往比使用开源工具简单快速,最主要是部署方便。
本章主要介绍基于wrap通用函数库glibc中的malloc/free等动态内存管理的机制,实现一些工作中常用的定位内存问题的工具。一开始,我也是满怀希望于valgrind能够帮助解决问题的,但是几次好不容易将valgrind部署好了,却发现valgrind起不到任何作用,一方面是valgrind给出的内存问题并没有覆盖到实际问题点,另外一方面是valgrind运行太过缓慢,工程启动超过40分钟不说,好不容易启动起来了,发现web登录超时无法使用,简直奔溃。
所以还是自己动手方能丰衣足食。
malloc/free wrap的实现之基于静态库
ld链接器选项的”–wrap,symbol”的作用描述如下:
Use a wrapper function for symbol. Any undefined reference to symbol will be resolved to “__wrap_symbol”. Any undefined reference to “__real_symbol” will be resolved to symbol.
上面的意思就是,在ld进行链接时,对于”UND”状态的symbol符号的引用将解析成为对”__wrap_symbol”符合的引用。同时,对于”UND”状态的”__real_symbol”符号将被解析为symbol。于是,当我们自己实现”__wrap_malloc”和”__wrap_free”函数后,通过添加编译参数”-Wl,–wrap,malloc -Wl,–wrap,free”,就可以实现代码中所有调用malloc/free的地方最终实际上调用的是我们实现的”__wrap_malloc/__wrap_free”函数。同时我们在完成自己想要完成的工作后,通过调用”__real_malloc/__real_free”函数,去调用libc库中真正的”malloc/free”实现。通过这么一来一去,我们可以搞很多有意思的事情。

下面通过一个非常简单的实例来进行验证:
/**
* simpleWrap.c
*/
#include <stdio.h>
void *__real_malloc(size_t);
void __real_free(void *);
void *__wrap_malloc(size_t size)
{
printf("in wrap malloc\n");
return __real_malloc(size);
}
void __wrap_free(void *ptr)
{
printf("in wrap free\n");
__real_free(ptr);
}
/**
* simpleWrap_test.c
*/
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
char *p = malloc(0);
free(p);
return 0;
}
执行’gcc -c simpleWrap.c; ar cru warp.a simpleWrap.o’进行编译生成静态库wrap.a.
执行’gcc simpleWrap_test.c wrap.a -Wl,–wrap,malloc -Wl,–wrap,free’进行编译链接,然后执行’./a.out’,得到如下输出:

上面的例子中共涉及两个文件,为了后面描述的清楚明白,这里我们称’simpleWrap_test.c’为目标文件,编译生成的’a.out’为目标代码,’simpleWrap.c’为我们 的调试文件,’wrap.a’为调试静态库。
在实现能够在实际复杂的生产环境下的调试工具之前,我们来思考一个问题, 如果上面的例子需要依赖其他的一些动态链接库,而且这些动态链接库里面也存在malloc/free的调用,我们如何将这些动态库里面的malloc/free也wrap到我们的调试库呢?现在我们修改一下什么的目标文件,同时添加另一个.c文件,这个.c文件最终会生成.so文件参与新目标文件的生成。
/**
* b.c
*/
#include <stdio.h>
#inlcude <stdlib.h>
void foo(void)
{
char *q = malloc(0);
printf("in foo\n");
}
/**
* simpleWrap_test.c
*/
#include <stdio.h>
#include <stdlib.h>
extern void foo(void);
int main(int argc, char *argv[])
{
char *p = malloc(0);
free(p);
foo();
return 0;
}
执行’gcc -fPIC -shared -o b.so b.c’生成动态链接库文件b.so,执行’readelf -s b.so’查看一下符号表:
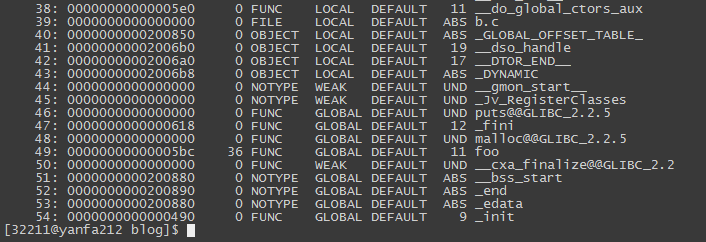
从上面的”UND malloc@@GLIBC_2.2.5”这一行可见,动态库b.so中的malloc在b.c文件进行编译时已经被指定最终会在链接时链接到glibc库中的malloc实现。
执行’gcc simpleWrap_test.c b.so wrap.a -Wl,–wrap,malloc -Wl,–wrap,free’生成新的目标文件a.out。运行结果如下:
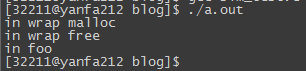
从结果也和我们的预期一样,b.so中的foo()函数中的malloc在执行时并没有打印”in malloc”语句,说明,通过上面的方法是无法做到wrap已经编译好了的动态库中的函数的。
所以,下面我们的目标是实现一个可以wrap掉工程中所有依赖的动态库中的malloc/free的调试库。当然,你可能已经猜到了,这个新的调试库应该也是一个动态库才行。
malloc/free wrap的实现之基于动态库
相对于静态库的实现机制来说,动态库的实现比较复杂,对于理解动态链接的过程涉及的知识原理有一定要求。所以在说明具体实现之前,先了解一下需要使用到的动态链接知识。
这方面的知识在 c开发笔记 里已经有一些介绍,下面补充其中没有说明的。
如果说上面的静态库实现方式是显示地借助于链接器ld的链接选项’–wrap’,那么动态库的实现可没有这样的选项协助,而是要借助于共享对象的全局符号介入(Global System Interpose)处理机制。
什么是全局符号介入,下面通过一个实例来说明。
/**
* a1.c
*/
#include <stdio.h>
void a(void)
{
printf("a1.c\n");
}
/**
* a2.c
*/
#include <stdio.h>
void a(void)
{
printf("a2.c\n");
}
/**
* main.c
*/
#include <stdio.h>
extern void a(void);
int main()
{
a();
for(;;);
return 0;
}
先执行:
‘gcc -fPIC -shared -o a1.so a1.c’
‘gcc -fPIC -shared -o a2.so a2.c’
分别生成a1.so和a2.so
然后执行:
‘gcc -o a1a2 main.c a1.so a2.so’
‘gcc -o a2a1 main.c a2.so a1.so’
分别执行a1a2和a2a1发现,前者输出a1.c而后者输出a2.c,这说明目标文件在最终执行链接时只链接了a1和a2中的一个,而且是谁在依赖关系前面就链接哪一个。
执行’readelf -d a1a2(a2a1)’查看目标文件中的.dynamic段如下:
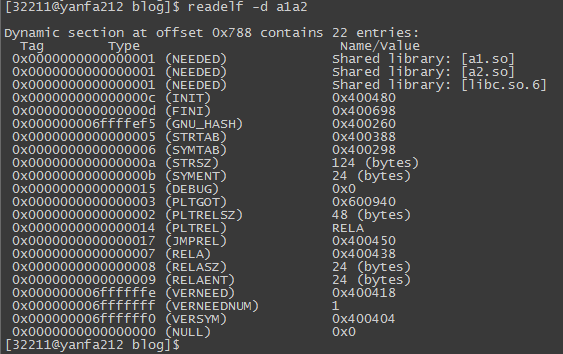
可以看到,a1.so和a2.so都被包含进来了,更进一步的我们执行’./a1a2 &’,然后通过’cat /proc/xxx/maps’来看一下进程地址空间中的内容:
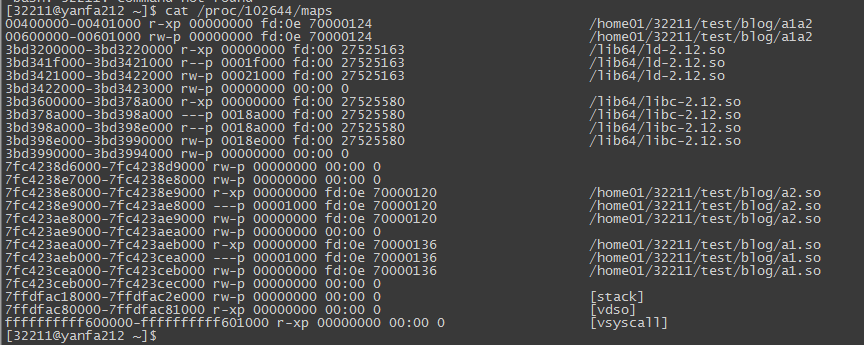
可以看到,a1.so和a2.so都被加载进内存了,但是a1.so和a2.so中相同的函数并没有起冲突。那么唯一的解释就是其中的一个函数被忽略了。这种一个共享对象里面的 全局符号被另一个共享对象全局符号覆盖的现象就被称为:全局符号介入.
在Linux下,动态链接器是这样处理全局符号介入问题的,那就是当一个符号需要被加入全局符号表时,如果相同的符号名已经存在,则后加的符号被忽略。从动态链接器的装载顺序来看,它是按照广度优先的顺序进行装载的。
在了解了上面的知识点后,下面开始代码的实现。
/**
* simpleWrap.c
*/
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <dlfcn.h>
#include <assert.h>
typedef void *(*malloc_func)(size_t);
typedef void (*free_func)(void *);
malloc_func real_malloc = NULL;
free_func real_free = NULL;
static char firstBuffer[1024];
void wrap_init(void)
{
static int once = 1;
if(!once)
{
return;
}
once = 0;
real_malloc = (malloc_func)dlsym(RTLD_NEXT, "malloc");
assert(real_malloc);
real_free = (free_func)dlsym(RTLD_NEXT, "free");
assert(real_free);
printf("wrap init done\n");
}
void *malloc(size_t size)
{
wrap_init();
printf("in wrap malloc\n");
return real_malloc(size);
}
void free(void *ptr)
{
wrap_init();
printf("in wrap free\n");
real_free(ptr);
}
/**
* main.c
*/
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
char *p = malloc(0);
free(p);
return 0;
}
执行”gcc -fPIC -shared -o libwrap.so simpleWrap.c” 生成我们的动态调试库libwrap.so
执行”gcc main.c libwrap.so -ldl” 生成目标程序a.out
执行”./a.out” 结果和上面静态库实现的一样。
经过完成上面的实例,下面我们就可以着手实现我们的工具了。
堆内存越界死机检测工具
实现的这个越界检测工具实际上是配合gdb的一个辅助工具,日常中我们使用gdb定位司机问题时会出现如下的场景:
- 使用gdb打印死机点的某个变量的值,发现是非法值。
- 执行’x/32xg xxxx’,查看这个内存地址所有值,如果发现都是异常值我们就会猜测应该是出现内存被踩的情况。
- 然后执行’x/32xg xxxx - 16’查看一下这个内存块的头信息是否完整,如果不完整说明的确就是被踩了。
- 确认被踩之后,我们就顺藤摸瓜,向上寻找最近的几个内存块,看看是哪个踩了我们的内存。
最后,在合理分析是哪个内存块越界篡改了底下的内存块时,下面我们最想知道的是这块内存对应的是哪个变量。只要我们知道这个内存对应的变量,我们就可以到对应代码段去分析越界访问的原因。但是,熟悉程序的编译链接和运行时原理后我们明白,我们是没有办法知道的。因为不够是elf文件还是运行时的环境中都记录没有堆内存地址和对应变量符号这样的信息。虽然没有这样的信息,但是我们清楚elf文件中全局符号表信息可以让我们记录一块内存被分配时的函数调用堆栈,这也是为什么gdb的bt命令可以获取完整调用堆栈的原因。
所以,我们自然想到如果我们可以记录下所有堆内存被分配时的函数调用堆栈,我们根据堆栈信息也可以轻松确定堆内存对应的变量。这样,这个堆内存越界检测工具的主要功能就很清楚了。下面的要考虑的问题就是,如何获取调用堆栈,将这些堆栈信息记录在哪里?如果清楚glibc中的堆内存管理机制和实现细节,那么就很容易知道该怎样做了。
所以下面我们需要补充一下运行时库glibc中堆内存管理的实现细节,具体参见
理解glibc中的堆内存管理细节后,发现我们要完成的工作很简单,获取分配内存时的调用堆栈信息,然后存储在内存块的头部。我们修改上面的malloc函数,实现如下:
void *malloc(size_t size)
{
char *ptr = NULL;
size_t total = size + sizeof(size_t *)*STACK_TRACE_DEPTH;
wrap_init();
ptr = real_malloc(total);
assert(ptr);
fill_retFunc_addr(&total, ptr, STACK_TRACE_DEPTH);
return ptr + sizeof(size_t *)*STACK_TRACE_DEPTH;
}
就这么简单的添加几行代码,我们的主体任务就已经完成了。更细节的实现封装在函数’fill_retFunc_addr()’中,代码也很简单,实现如下:
static void fill_retFunc_addr(size_t *sp, char *ptr, size_t depth)
{
void *trace[STACK_TRACE_DEPTH] = {0};
int len;
int i;
(void)sp;
(void)depth;
len = backtrace(trace, STACK_TRACE_DEPTH - 1);
for(i = 0; i < len; i++)
{
*((size_t *)ptr + i) = trace[i];
}
/**
* 添加MAGIC NUM,用于判断是否是我们的malloc分配的内存,
* 这样我们的free可以针对性的正确处理。另外,MAGIC NUM的可以
* 帮助我们快速定位内存块的位置。
*/
*((size_t *)ptr + STACK_TRACE_DEPTH - 1) = MAGIC_NUM;
}
然后,我们对应的实现我们的free函数,代码更加简单:
void free(void *ptr)
{
unsigned char *real_addr;
wrap_init();
if(!ptr)
return;
real_addr = get_real_addr(ptr);
real_free(real_addr);
return;
}
到目前为止,主体功能基本实现了,这时编译成动态库然后运行测试程序,你会发现一下子就死机了,使用gdb跟踪发现,在mallco调用时出现了无限递归。这是为什么呢?
这是因为我们在’fill_retFunc_addr()’中使用的backtrace函数内部需要调用malloc,这样自然就出现了递归。那么如何消除这种递归情况呢?最直接的想法就是使用全局变量记录本次malloc是用backtrace调用的,这时就直接调用glibc中的malloc然后返回。这样就可以避免死循环递归了,但是因为一个进程中会有众多的不同线程调用malloc,使用普通的全局变量肯定不行,下面介绍pthread库中提供的thread-specific data management蔟函数接口:
The pthread_getspecific() function shall return the value currently bound to the specified key on behalf of the calling thread. The pthread_setspecific() function shall associate a thread-specific value with a key obtained via a previous call to phread_key_create(). Different threads may bind different values to the same key. These values are typically pointers to blocks of dynamically allocated memory that have been reserved for usr by the calling thread.
上面描述的特性真好符合我们的需求,不同的线程可以设置不同的变量值到同一个key上,下面是添加的代码:
首先在wrap_init()函数中添加初始化代码:
void wrap_init(void)
{
int ret;
...
ret = pthread_key_create(&isNeedCallRealMalloc, NULL);
assert(ret == 0);
...
}
然后在malloc函数中添加判断处理:
void *malloc(size_t size)
{
...
if(pthread_getspecific(isNeedCallRealMalloc))
{
return real_malloc(size);
}
....
}
最后就是在调用backtrace函数前后进行设值:
static void fill_retFunc_addr(size_t *sp, char *ptr, size_t depth)
{
...
pthread_setspecific(isNeedCallRealMalloc, (void *)true);
len = backtrace(...);
pthread_setspecific(isNeedCallRealMalloc, (void *)false);
...
}
这样递归死循环的问题就解决了,但是我们的任务还没有完成,我们目前只是实现了malloc和free函数,然而实际项目中还会经常调用calloc和realloc这两个内存申请接口,同时还有memalign、valloc、posix_memalign这三个不常用的内存申请接口。为了工具的实用性,至少得实现calloc和realloc。
calloc的实现比较简单,如下:
void calloc(size_t nmemb, size_t size)
{
void *ret = NULL;
if(nmemb == 0 || size == 0)
{
return malloc(0);
}
ret = malloc(nmemb*size);
if(ret) memset(ret, 0, nmemb*size);
return ret;
}
realloc的实现复杂一点,因为涉及到内存块的调整,具体参见
好了,现在编译新的调试库跑测试看一看,咦?程序刚跑就死机,使用gdb跟踪发现死在了real_malloc为空指针,分析后发现,原来dlsym函数内部会调用一次calloc,这就尴尬了,出现了先有鸡还是先有蛋的问题。不过因为dlsym内部只是调用一次calloc,解决起来还是比较简单的,方法是借用静态内存,修改代码如下:
首先修改calloc函数:
calloc(size_t nmemb, size_t size)
{
static int isfirst = true;
...
if(isfirst)
{
isfirst = false;
return firstBuffer;
}
...
}
然后是在free实现中做匹配修改:
void free(void *ptr)
{
...
if(ptr == firstBuffer)
{
return;
}
...
}
好了,重新编译,测试ok,现在终于大功告成了,不过在进行实证演示工具效果前,还要补充说明一下,上面的非常容易出错的地方,就是get_real_size()函数的实现,首先来看一下代码:
static size_t get_real_size(unsigned char *addr)
{
size_t chunk_size = *(size_t *)(addr - sizeof(size_t)) & (~(2*sizeof(size_t) - 1));
int isMemMap = *(size_t *)(addr - sizeof(size_t)) & (1 << 1);
return isMemMap ? chunk_size - sizeof(void *)*2 : chunk_size - sizeof(void *);
}
容易出错的就是最后的返回值计算,这里涉及到了chunk中的空间复用机制。具体见
内存泄露检测工具
和内存越界访问死机问题一样,内存泄漏往往也是非常棘手的问题,尤其是当涉及到很多第三方的开源库时。靠单纯的走读代码定位泄漏点,犹如大海捞针,这时简单好用的检测工具就显得尤为重要。
这里介绍的内存泄漏检测工具是在实战中洗礼出来的,解决了实际项目中很多棘手的内存泄漏难题,具有很强实战意义。项目开源在github上。
实现原理
原理来源于需求,在实现这个工具时,第一个要思考的就是我们在谈内存泄漏检测时,我们的具体需求是什么?需求也是由等级的,
- 当前的进程是否存在内存泄漏?
- 如果确实存在泄漏,又是哪个线程或者哪些线程在泄漏?
- 知道哪个线程存在泄漏后,那么这个线程中哪里的代码段(函数调用堆栈)导致的泄漏?
想出能够解决上面问题的方法就是这个工具的实现原理。其中第一点linux自带的free、top命令或者直接cat /proc目录下的meminfo文件都可以知晓。但是,解决第一点是检测工具具有实用性的前提。
这里介绍的工具实现了两个不同的工作模式来分别解决第二和第三点需求,因为解决这两点需求所需的代价是不一样的。如下图,
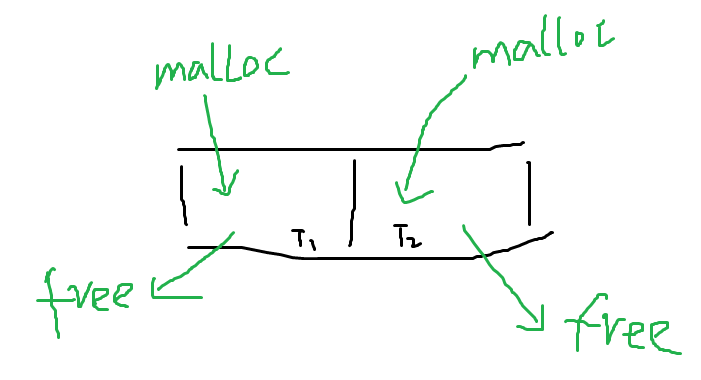
假设我们的进程中只有两个线程,每个线程调用malloc申请的地址都会在本线程中被free掉,那么我们就可以以线程为单位,统计一段时间内,每个线程的malloc和free次数,如果free的次数明显少于malloc次数,说明存在内存泄漏。主要实现代码大概如下:
static void malloc_record(void *ptr, size_t size)
{
int tid = (int)syscall(SYS_gettid);
stat_node_t *node = &hash_table[tid];
if(node->tid == tid)
{
node->malloc++;
...
}
else
{
node->malloc = 1;
node->free = 0;
...
}
...
}
static void free_record(void *ptr)
{
int tid = (int)syscall(SYS_gettid);
stat_node_t *node = &hash_table[tid];
if(node->tid == tid)
{
node->free++;
...
}
...
}
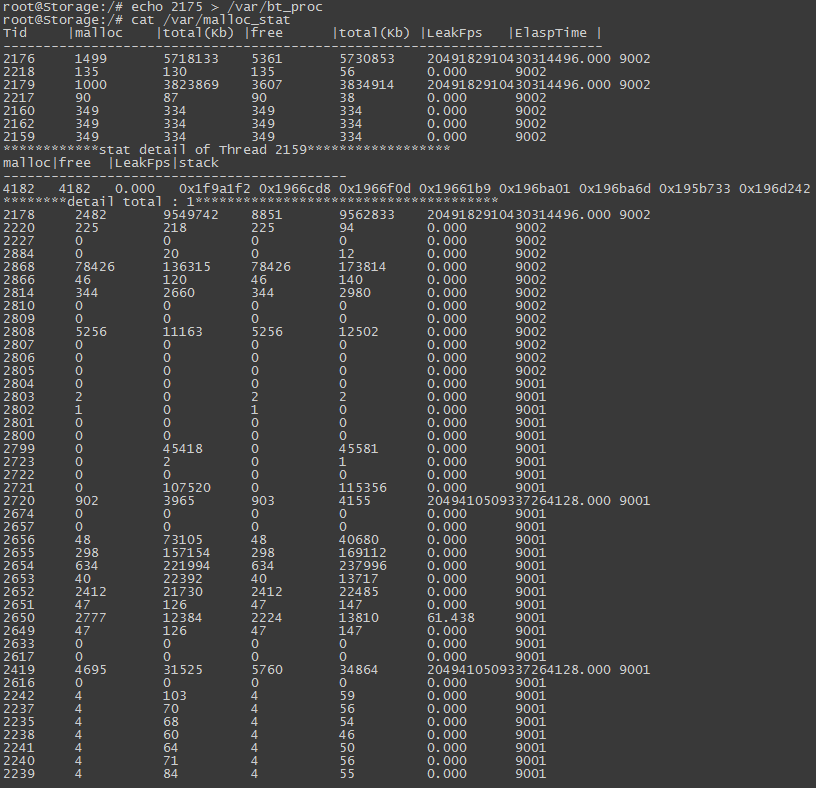
这样一思考,发现实现第二点需求还是很简单的。本工具在启动时默认就处于这种解决模式下。实际测试发现,检测 结果的误报率很高,某次实测输入结果如下:
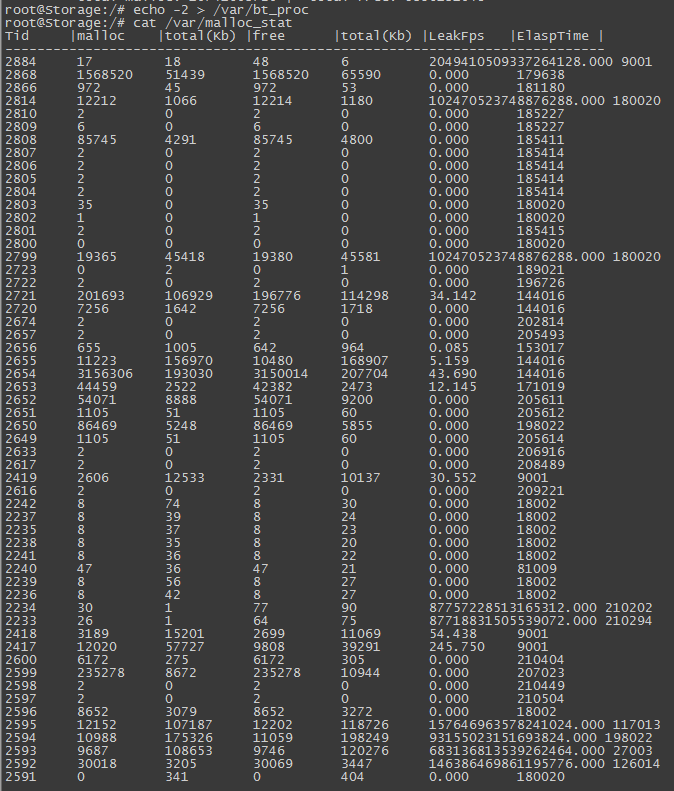
稍微深入一点思考就会知道,像上面这么简单的算法肯定是由问题的,因为调用malloc和对应free的线程很可能不是同一个,也就是会出现如下图所示情况:
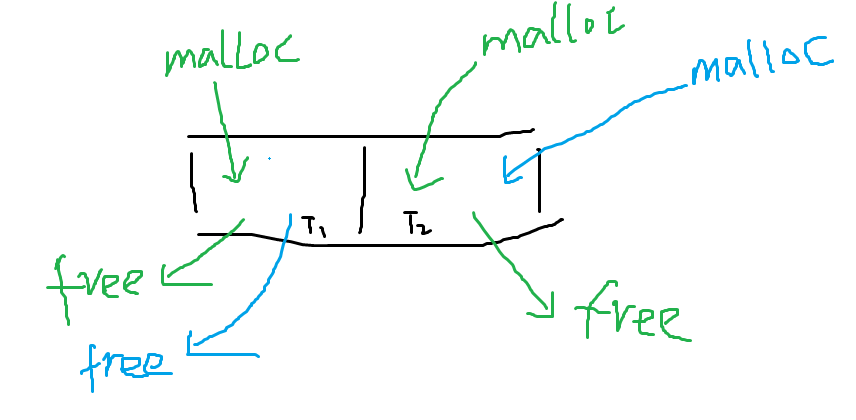
也就是说,我们在记录free时,不能简单的通过syscall(SYS_gettid)获取当前的线程作为被释放地址被申请时所在的线程,而是应该通过入参ptr指针获取 该地址被申请时所在的线程。实现这个功能其实就是需要在malloc时记录保存地址对应的线程号信息,相对于需要临时保存[addr,tid]这样一个键值对,addr是 键,tid是值。这样当我们记录free时,通过这个地址这个键可以很轻松获取其申请时所属的线程号。
继续思考第三点需求时会发现,我们需要记录保存[addr,stack]这样的键值对,所以为了实现的简便性,完全可以将这两者统一起来,即记录[addr,{tid,stack}] 这样的键值对。为了搜索的时间复杂度最低,显然使用哈希表是很合适的。哈希表算法使用的方法见这篇文档
当我们echo有效的thread id到/var/bt_proc文件时就进入这种解决模式下,因为所需记录很多的堆栈信息,所以这种模式对内存和cpu有不少开销。不过,进入
这种模式后,检测的准确性明显提高,对应的结果见下图: