更新于2023-01-01
网络诊断
netstat工具
- 查看TCP连接状态分布
netstat -ant|awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}'
TIME_WAIT 34
SYN_SENT 1
LISTEN 32
ESTABLISHED 6
应用协议
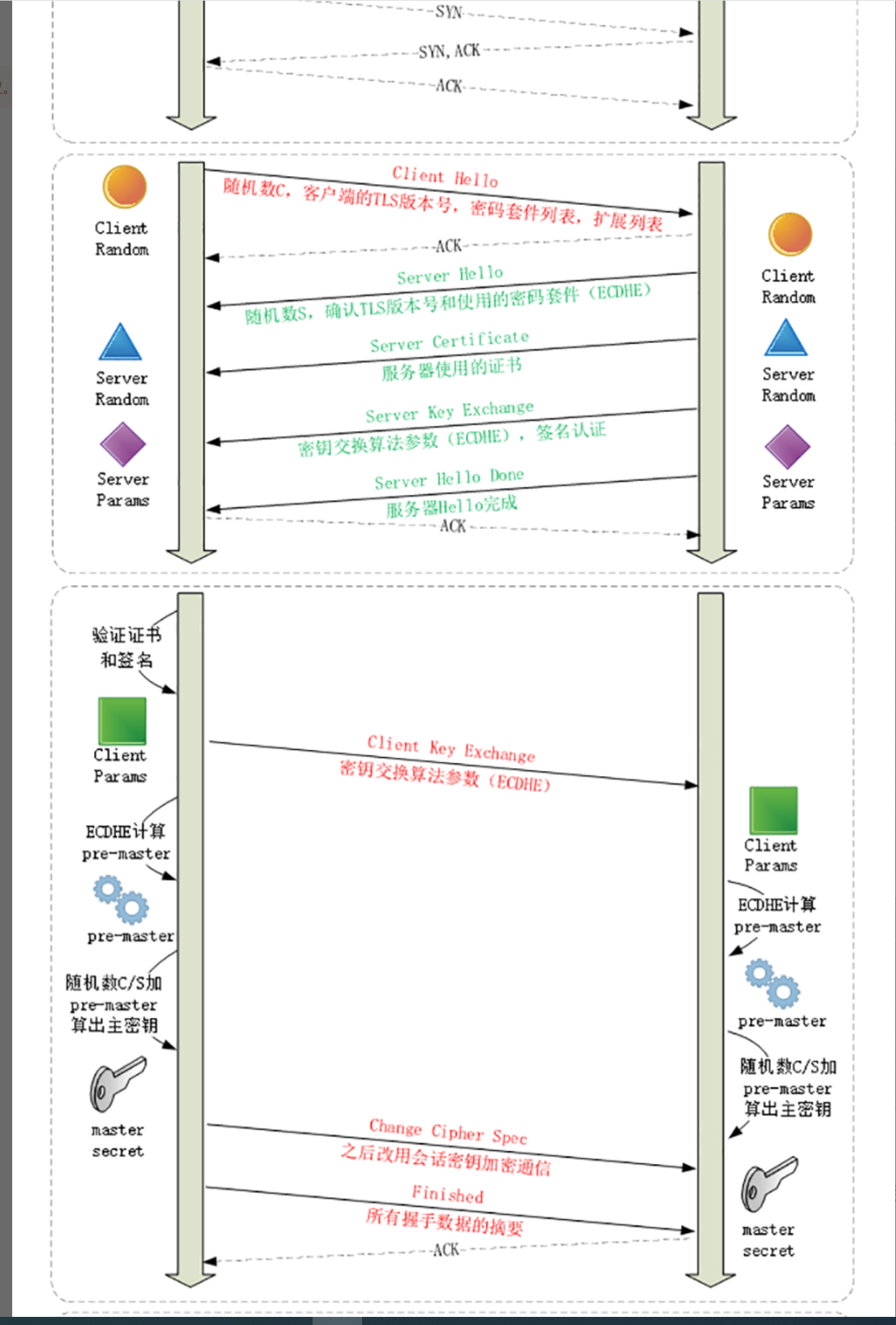
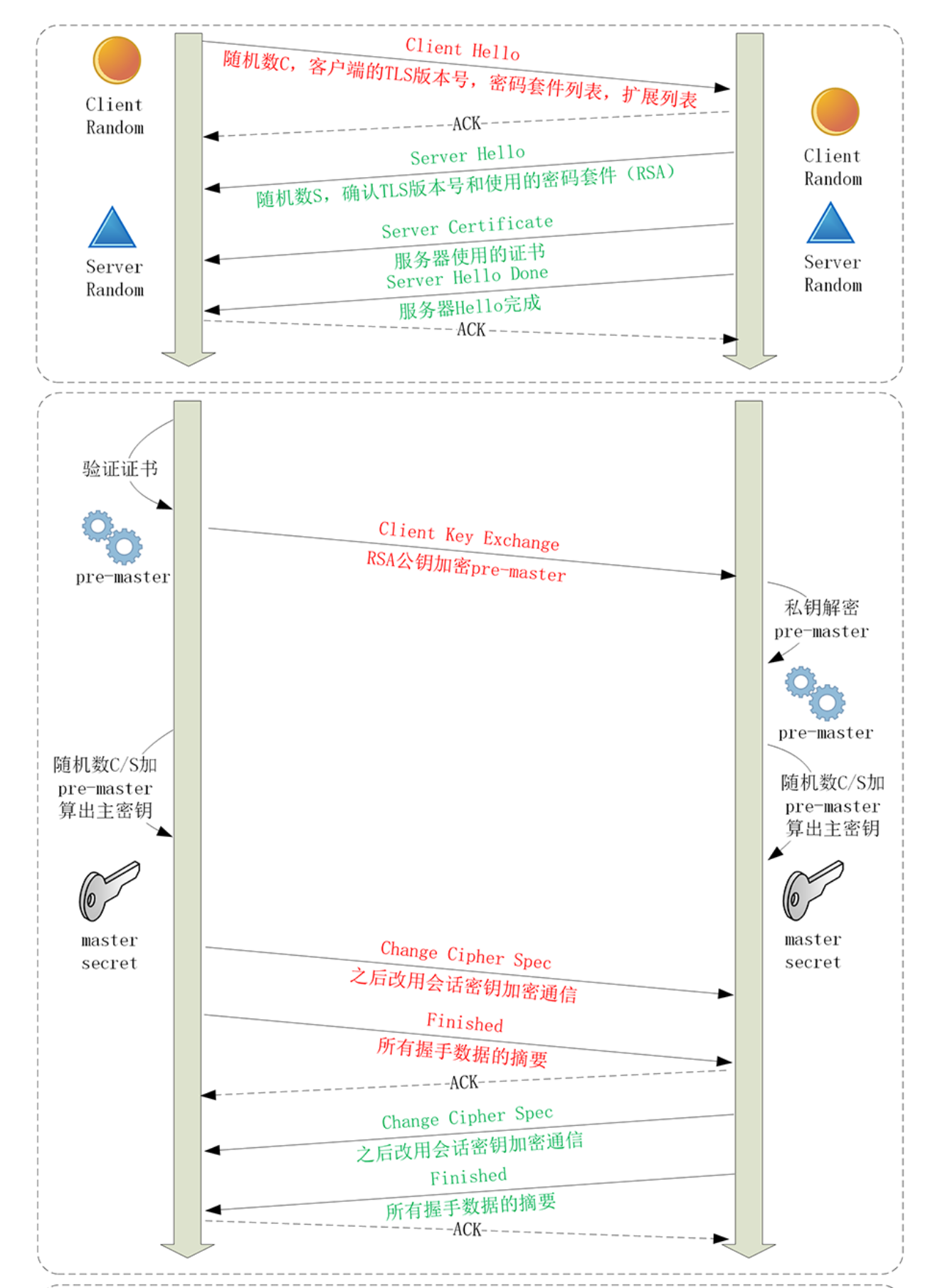
tls握手过程
- ECDHE握手过程
(1):客户端随机生成随机值Ra,计算Pa(x, y) = Ra * Q(x, y),Q(x, y)为全世界公认的某个椭圆曲线算法的基点。将Pa(x, y)发送至服务器。
(2):服务器随机生成随机值Rb,计算Pb(x,y) = Rb * Q(x, y)。将Pb(x, y)发送至客户端。
(3):客户端计算Sa(x, y) = Ra * Pb(x, y);服务器计算Sb(x, y) = Rb *Pa(x, y)
(4):算法保证了Sa = Sb = S,提取其中的S的x向量作为密钥(预主密钥)。
- 主流基于ECDHE密钥交换算法
- 传统基于RSA密钥交换算法
网络调试工具使用
netstat
netstat -tulpn --raw
基础知识
-
MTU是ip层(三层)的定义,MSS是tcp层(四层)的定义,
MTU(1500bytes) = ip头部(20bytes) + TCP头部(20bytes) + MSS(1460bytes) -
window scale 作为tcp option中的设置,只出现在TCP握手阶段,它表示将原始窗口值扩大多少倍。
-
发送窗口等于拥塞窗口和对方接受窗口中的较小值。
头文件
数据链路层
/user/include/net/ethernet.h中定义了以太网帧结构,如:
struct ether_addr
struct ether_header
ip层
user/include/net/if_arp.h中定义了arp帧头结构, struct arphdr
user/include/netinet/if_ether.h中定义了arp数据报结构, struct ether_arp
ipv4分类
# From IANA IPv4 Special-Purpose Address Registry
# http://www.iana.org/assignments/iana-ipv4-special-registry/iana-ipv4-special-registry.xhtml
# Updated 2013-05-22
0.0.0.0/8 # RFC1122: "This host on this network"
10.0.0.0/8 # RFC1918: Private-Use
100.64.0.0/10 # RFC6598: Shared Address Space
127.0.0.0/8 # RFC1122: Loopback
169.254.0.0/16 # RFC3927: Link Local
172.16.0.0/12 # RFC1918: Private-Use
192.0.0.0/24 # RFC6890: IETF Protocol Assignments
192.0.2.0/24 # RFC5737: Documentation (TEST-NET-1)
192.88.99.0/24 # RFC3068: 6to4 Relay Anycast
192.168.0.0/16 # RFC1918: Private-Use
198.18.0.0/15 # RFC2544: Benchmarking
198.51.100.0/24 # RFC5737: Documentation (TEST-NET-2)
203.0.113.0/24 # RFC5737: Documentation (TEST-NET-3)
240.0.0.0/4 # RFC1112: Reserved
255.255.255.255/32 # RFC0919: Limited Broadcast
# From IANA Multicast Address Space Registry
# http://www.iana.org/assignments/multicast-addresses/multicast-addresses.xhtml
# Updated 2013-06-25
224.0.0.0/4 # RFC5771: Multicast/Reserved
以太网和IEEE802封装
以太网这个术语是在1982年由几个公司联合公布的一个标准,它是当今TCP/IP采用的主要的局域网技术。它采用一种称为CSMA/CD的媒体接入方法,速率为10Mb/s,地址为48bit。
几年后,IEEE802委员会公布了一个稍有不同的标准集,其中802.3针对整个CSMA/CD网络,802.4针对令牌总线网络,802.5针对了令牌环网。这三种的个性特征由802.2标准定义,那就是802网络共有的逻辑链路控制(LLC)。不幸的是,802.2和802.3定义了一个与以太网不同的帧格式,如下图:
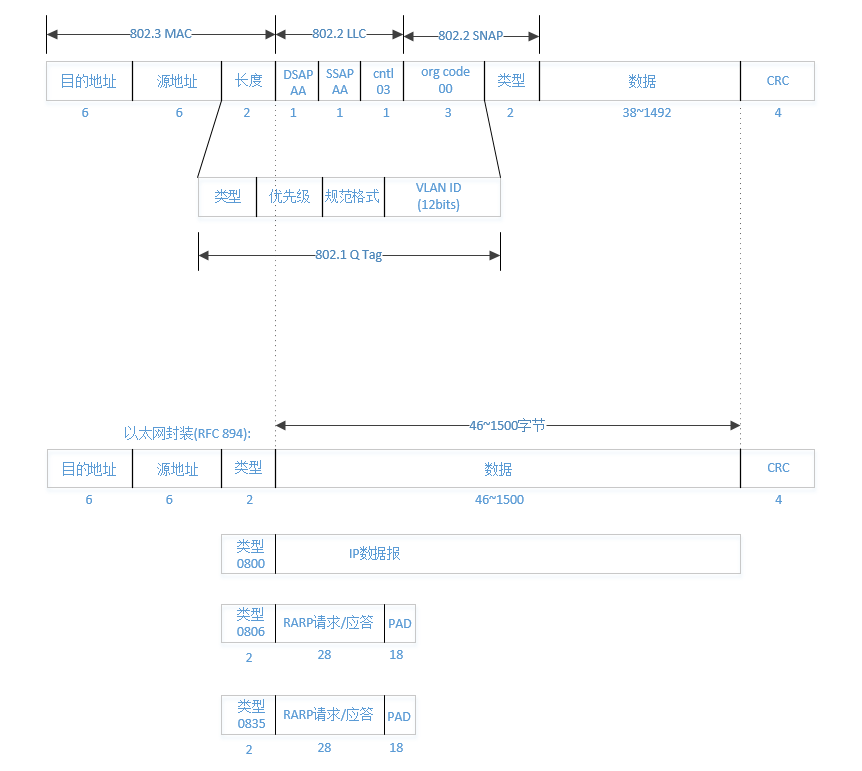
在802标准定义的帧格式中,长度字段是指它后续数据的字节长度,但不包括CRC检验码;以太网的类型字段定义了后续数据的类型。 在802标准定义的格式中,类型字段则由后续的子网接入协议(sub-network access protocol, SNAP)的首部给出。幸运的是,802定义的有效长度值与以太网的 有效类型值都不相同,这样,就可以对两种帧格式进行区分了。
另外,上图也给出了802.1的格式定义,802.1 Q Tag主要用来实现局域网的虚拟隔离,VLAN。
802.3标准定义的帧和以太网的帧都有最小长度要求。802.3规定数据部分必须至少为38字节,而对以太网,则要求最少要46字节,为了保证这一点,必须在不足的空间插入填充(pad)字节。
套接字地址结构
大多数套接字函数都需要一个指向套接字地址结构的指针作为参数。每个协议族都定义它自己的套接字地址结构。这些结构的名字均以sockaddr_开头,并以对应每个协议族的唯一后缀结尾。比如IPv4套接字地址结构即为sockaddr_in,它定义在<netinet/in.h>头文件中:
struct in_addr{
in_addr_t s_addr;
};
struct sockaddr_in{
uint8_t sin_len; /* length of structure, 有些实现中这个字段不存在 */
sa_family_t sin_family;
in_port_t sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
关于上面的IPv4套接字地址结构实现需要注意两个问题:
-
长度字段sin_len是为增加对OSI协议的支持而随4.3BSD-Reno添加的。在此之前,第一个成员是sin_family,它是一个无符号短整形(unsigned short)。因为并不是 所有的厂家都支持套接字地址的长度字段,所以为了实现的兼容性,在支持sin_len的实现中,sa_family_t定义为一个8位的无符号整数,而在不支持长度的实现中,它 则是一个16位的无符号整数。
-
因为历史遗留的原因,sin_addr字段是一个机构,而不仅仅是一个in_addr_t类型的无符号长整型。虽然serv.sin_addr和serv.sin_addr.s_addr引用的是同一个 32位IPv4地址,但是将它作为函数的参数时要注意准确性,因为变压器对传递结构和传递整形的处理是完全不同的。
上面描述的是IPv4协议族对应的套接字地址格式,其他协议族也对应的套接字地址格式,当这些地址作为参数传递进任何套接字函数时,套接字地址结构总是以指针形式
来传递。为了兼容不同的地址指针类型,得想一个办法。有了ANSI C后我们很清楚解决办法很简单,就是使用通用的指针类型 - void *,然而套接字函数是在ANSI C之前定义的, 所以在1982年采取的办法是在<sys/socket.h>头文件中定义一个通用的套接字地址结构,如下:
struct sockaddr{
uint8_t sa_len;
sa_family_t sa_family;
char sa_data[14];
}
于是套接字函数被定义为以指向某个通用套接字地址结构的一个指针作为其参数之一,这正如bind函数的ANSI C函数原型所示:
int bind(int, struct sockaddr *, socklen_t);
Multicast(多播)
搞公网扫描时发现对基于multicast的upnp协议应用范围不是很了解,研究多播网络实现后,豁然开朗。
单播和广播是寻址的两个极端,多播则意在两者之间提供一个补充和折衷,多播数据只应该由它感兴趣的接口接收。另外,相比于广播只能在局域网内使用,而多播则可以跨广域网使用。
虽然多播可以跨广域网使用,但不能简单的认为可以在局域网内使用upnp那样在广域网内使用,因为事情没有那么简单,这里先按下不表。
多播地址
IPv4的D类地址(从224.0.0.0到239.255.225.225)是IPv4多播地址,D类地址的低序28位构成多播组ID(group ID),整个32位地址则称之为组地址(group address)。
我们知道网络中数据报的传输先要寻址,而寻址不但需要IP地址,更重要的是以太网地址(MAC address),为什么网络包的传输即需要IP地址又需要MAC地址呢?详细完备的说明这里先按下不表,通过后面介绍多播会话流程中的底层细节就会有清晰感性的认识了。
为了节省mac地址,已经考虑到多播的实际应用场景的特殊性,多播地址和mac地址存在一个非一对一的映射关系,
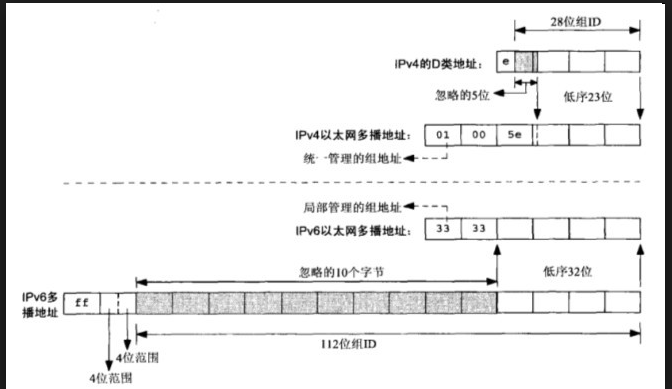
如上图,以太网地址的高序24位总是01:00:5e,下一位总是0,低序23位复制多播地址ID的低序23位。这意味着多播组ID的高序5位是被忽略的,也就是每32个多播地址共享同一个mac地址。我们很直观的会想到,那数据报的寻址不是会出问题吗?其实不然,具体见后面分析。
以太网地址首字节的低序2位表明该地址是一个统一管理的组地址。统一管理属性位意味着以太网的高序24位由IEEE分配,组地址属性位由接收接口识别并进行特殊处理。
下面是若干个特殊的IPv4多播地址:
-
224.0.0.1 是所有主机组。子网上所有具有多播能力的节点(主机、路由器等等)必须在所有具有多播能力的接口上加入该组。
-
224.0.0.2 是所有路由器组。子网上所有多播路由器必须在所有具有多播能力的接口上加入该组。
-
224.0.0.0 ~ 224.0.0.255之间的地址(即224.0.0.0/24)称为链路局部(link local)的多播地址。这些地址是为低级拓扑发现和维护协议保留的。多播路由器从不转发以这些地址为目的地址的数据报。
多播地址的范围
多播协议中一个重要部分就是多播的通信范围,即多播数据报的游走范围。这也是理解upnp协议实用范围的一个重要方面。
IPv6多播地址显式存在一个4位的范围字段,用于指定多播数据报能够游走的范围,IPv6分组还有一个跳限(hop limit)字段,用于限制分组路由器转发的次数。下面是如干个已经分配给范围字段的值:
1: 接口局部的(interface-local)。
2: 链路局部的(link-local)。
4: 管区局部的(admi-lcoal)。
5: 网点局部的(size-local)。
8: 组织机构局部的(organization-lcoal)。
14: 全球的(global)。
接口局部数据报不准由接口输出,链路局部数据报不可由路由器转发。其他的具体定义由该网点或者组织机构的多播路由器管理员决定。
IPv4多播数据报没有单独的范围字段,因为历史沿用关系,IPv4首部中的TTL字段兼用作多播范围字段:0意为接口局部,1意为链路局部,2~32意为网点局部,33~64意为地区局部,65~128意为大洲局部,129~255意为无范围限制(global)。
这就是为什么setsockopt()提供了IP_MULTICAST_TTL选项设置TTL的原因。
如果按照范围划分,会把介于239.0.0.0到239.255.255.255之间的地址定义为可管理地址划分范围的IPv4多播空间(administratively scoped IPv4 multicast space)。它占据多播地址空间的高端,该范围内的地址右组织机构内部分配,但是不保证跨组织机构边界的唯一性。任何组织机构必须把它的边界路由器配置成禁止转发以这些地址为目的地址的多播数据报。
upnp的多播地址239.255.255.250正是处于这一区间内,所以在公网上进行mutilcast upnp肯定是不可行的。
TCP套接字编程
bind函数
#include <sys/socket.h>
/**
* return:成功返回0,否则返回-1
*/
int bind(int sockfd, const struct sockaddr *myaddr, socklen_t addrlen);
用一句话概括bind函数的作用就是-bind assigns a name to an unnamed socket。这里说的name就是第二个参数描述的特定协议的地址结构指针,struct sockaddr结构主要包含ip地址和端口号,理解bind函数的作用,主要就是弄清楚内核和调用bind函数的进程在套接字、地址及端口这三个对象上的行为。
对于TCP,调用bind函数可以指定一个端口号,或者一个IP地址,也可以两者都指定,还可以两者都不指定。
-
TCP客户端通常不会调用bind函数,这样当客户端调用connetc或者listen时,内核会为相应的套接字选择一个临时端口,再根据所用外出网络接口来选择源IP地址。
-
因为服务器是通过众所周知的端口被大家认识的,所以一般TCP服务端在启动时都会绑定一个端口,而是否绑定IP地址则视具体情况而定:
-
不绑定IP(myaddr.sin_addr.s_addr = INADDR_ANY),也可称为绑定通配地址,当一个连接到达时,服务器通过调用
getsockname函数获取来自客户的目的IP地址,然后服务器根据这个客户连接所发往的IP地址来处理客户的请求。 -
绑定非通配IP地址的常见例子是在为多个组织提供web服务器的主机上。不同组织对应不同的域名和IP地址,然后,把所有这些IP地址都定义成单个网络接口的别名(比如使用ifconfig命令的alias选项来定义),这么一来,IP层将接受到所有目的地为任何一个别名地址的外来数据报。最后,为每个组织启动一个HTTP服务器的副本,每个副本仅仅绑定相应组织的IP地址。
-
TCP客户端绑定非通配IP地址的好处是:把一个给定的目的IP地址解复用到一个给定的服务器进程是由内核完成的。
单纯通过观察bind函数的定义我们应该可以知道,如果让内核来为套接字选择一个临时端口号,那么函数bind并不会返回所选择的值。因为bind函数的第二个入参的有
const限定词,它无法返回所选值。为了达到内核所选择的这个临时端口值,必须调用getsockname函数。
select函数
#include <sys/select.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *execptfds, struct timeval *timeout);
在linux下使用select函数时,要特别注意timeout这个参数。
今天测试程序性能时发现,程序运行后cpu占用特别高,很快飙升并稳定在107%左右。使用perf性能工具分析后,很快定位到时程序一处select函数调用最占用了 大部分CPU时间。
问题代码段逻辑大致如下:
{
...
struct timeval tv;
tv.tv_sec = 1;
tv.tv_usec = 0;
while(...){
ret = select(... &tv);
...
}
...
}
这段代码在其他非linux系统下运行是没有问题的,但是在linux下运行会出现CPU占用飙升的问题。原因可以通过man select中的一句话看出来:
On linux, select() modifies timeout to reflect the amount of time not slept.
也就是说在linux系统下,select()会将timeout值修改为剩余未休眠的时间,这个修改后的值很可能是很小或者为0,那么select()就从变成立即返回了。
所以正确的调用方式如下:
{
...
while(...){
struct timeval tv;
tv.tv_sec = 1;
tv.tv_usec = 0;
ret = select(... &tv);
...
}
...
}
原始套接字编程
原始套接字的输出
原始套接字让应用层程序拥有任意创建和修改数据包的功能,传统UNIX系统如4.xBSD只提供了AF_INET域,而Linux添加了PF_PACKET域,调用socket函数传入不同的域,使得应用程序获得不同程度操作数据包的功能。
比如socket(AF_INET, SOCK_RAW, htons(ETH_P_ALL))创建的socket,通过setsockopt()设置IP_HDRINCL选项可以让应用程序创建ip层数据,而无法修改链路层的数据。
而socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL))创建的socket, 可以让应用层直接定义链路层数据。
除了域的不同影响原始套接字的输出行为, 另外protocol参数也起类似作用,比如socket(PF_PAKCET, SOCK_DGRAM, htons(ETH_P_ALL)), 这时,内核负责创建链路层数据,在调用sendto函数时只能传入IP层开始的数据。
如果我们调用socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL))创建socket进行数据包发送,那么我们在调用sendto函数时只能设置struct sockaddr_ll类型的地址,该地址主要是告诉内核,应该向哪个网卡输出这个数据包。
int sock = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
if (sock < 0)
{
return;
}
struct sockaddr_ll saddr_ll = { 0 };
struct ifreq ifr;
strcpy(ifr.ifr_name, "eth0");
ioctl(sock, SIOCGIFINDEX, &ifr);
saddr_ll.sll_ifindex = ifr.ifr_ifindex;
saddr_ll.sll_family = AF_PACKET;
sendto(sock, p, size, 0, (struct sockaddr *)&saddr_ll, sizeof(struct sockaddr_ll));
原始套接字的输入
内核是否把接收到的ip数据报传递到原始套接字,遵循以下规则:
- 接收到的UDP分组和TCP分组绝不会传递到任何原始套接字。
- 内核不认识其协议字段的所有IP数据报传递到原始套接字。
- 所有的IGMP和ICMP分组在内核处理完后都会传递到原始套接字。
- 在内核有需要传递到原始套接字的IP数据报时,它将检查进程上所有原始套接字,并进行如下3个测试:
- 如果创建的这个原始套接字时指定了非0的协议参数,那么接收到的数据报的协议字段必须匹配该值。
- 如果这个原始套接字已由bind调用绑定了某个本地ip地址,那么接收到的数据报的目的ip地址必须匹配这个绑定的地址。
- 如果这个原始套接字已由connect调用指定了某个外地ip地址,那么接收到的数据报的源IP必须匹配这已连接地址。
根据以上可知,如果一个原始套接字以0作为第三个参数创建,而且即未对它调用bind,也未调用connect, 那么该套接字将接收由内核传递到原始套接字的每个原始数据报的一个副本。
struct ip VS struct iphdr
/* <linux/ip.h> */
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__u16 tot_len;
__u16 id;
__u16 frag_off;
__u8 ttl;
__u8 protocol;
__u16 check;
__u32 saddr;
__u32 daddr;
/*The options start here. */
};
/* <netinet/ip.h> */
struct ip {
#if BYTE_ORDER == LITTLE_ENDIAN
unsigned int ip_hl:4; /* header length */
unsigned int ip_v:4; /* version */
#endif
#if BYTE_ORDER == BIG_ENDIAN
unsigned int ip_v:4; /* version */
unsigned int ip_hl:4; /* header length */
#endif
u_char ip_tos; /* type of service */
short ip_len; /* total length */
u_short ip_id; /* identification */
short ip_off; /* fragment offset field */
#define IP_DF 0x4000 /* dont fragment flag */
#define IP_MF 0x2000 /* more fragments flag */
u_char ip_ttl; /* time to live */
u_char ip_p; /* protocol */
u_short ip_sum; /* checksum */
struct in_addr ip_src,ip_dst; /* source and dest address */
};
struct ip和struct iphdr都是描述ip数据报头的结构体,观察其内部元素也基本一致,他们主要的区别可以从它们所属的目录看出来,struct iphdr位于linux子目录下,说明该头文件只能用于linux系统下的程序,而struct ip则在类unix的所有系统下通用。
网络工具
iptables
basic
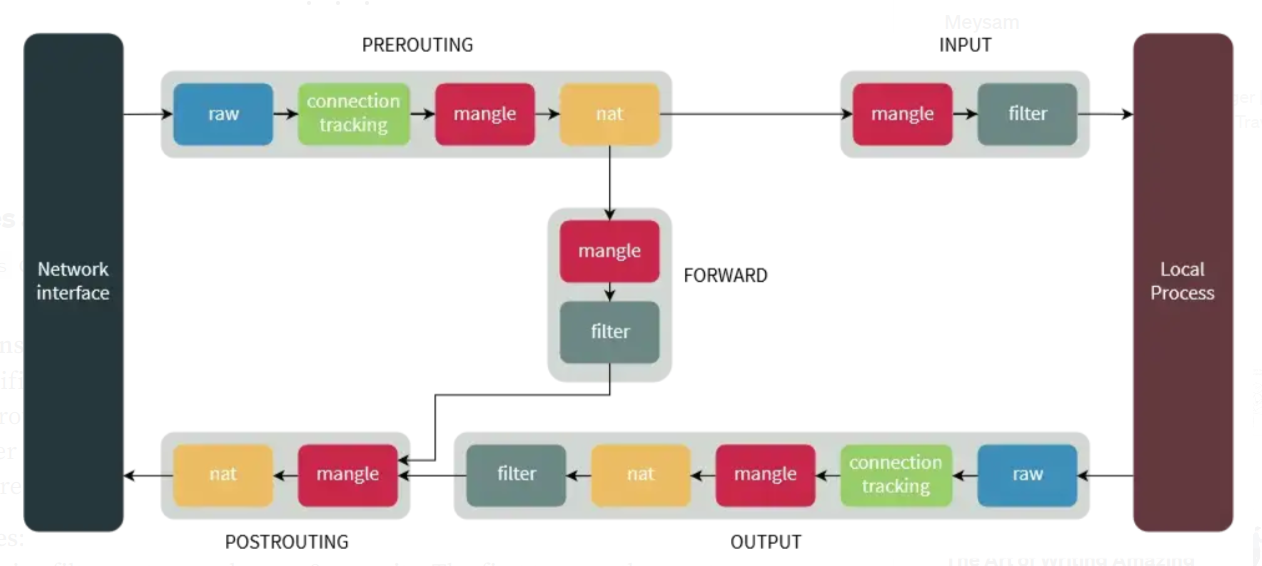
iptables主要包含三大组成部分,tables, chains, targets。
-
tables
filter是默认的table,起到firewall给过滤package功能nat是负责网络地址的转换,在ipv4网络中至关重要的一个功能mangle主要是用来更改数据包的内容security用于强制访问控制网络安全raw主要是用于配置package免于connection tracking
-
chains
从上图可以很清晰直观的看出prerouting, input, forward, output & postrouting这5个chain所处的位置和作用。
-
targets
- 内建的3个主要targets,
DROP,ACCEPT,RETURN - 扩展模块支持的39个其他targets, 比如
DNAT,MASQUERADE,REJECT等等
- 内建的3个主要targets,
实战
修改TCP握手报文的MSS
iptables -A FORWARD -p tcp --tcp-flags SYN SYN -j TCPMSS --set-mss 1400
配置Tun0网卡访问外网
使用虚拟网卡tun是实现vpn相关功能的基础,如何使写入tun网卡的数据可以出去呢?进行ip forward加上snat即可。
- 执行sudo sysctl -w net.ipv4.ip_forward=1 使能系统ip forward功能,这样写入tun网卡的数据可以被内核送到forward chain上。
- 执行sudo iptables -t nat -A POSTROUTING -s 100.64.0.0/16 ! -d 100.64.0.0/16 -j SNAT –to $ip
其中的$ip是连接网络的网卡ip, 这条命令有个问题是如果设备的网卡ip发送变化就会snat失败, 所以可以使用MASQUERADE进行snat配置,
sudo iptables -t nat -A POSTROUTING -s 100.64.0.0/16 -o $eth -j MASQUERADE这条命令是指定了snat的网卡,而且无论这个网卡ip怎么变化,都可以自动进行snat - 执行sudo iptables -i FORWARD -s 100.64.0.0/16 -j ACCEPT
- 执行sudo iptables -i FORWARD -m state –state RELATED,ESTABLISHED -j ACCEPT
最后这条命令很重要,否则一些数据包无法被forward, 比如实测中发现当server返回的SYN包flags设置了ECN, 如果 没有设置这条rule,那么数据会被丢弃
ifconfig、route、arp和netstat这些统称为net-tools的工具是大家常用的管理和配置linux网络的工具。这些工具来自BSD TCP/IP工具箱,并且这些工具是用来 配置较旧的内核版本的,所以现在很多Linux发行商已经开始淘汰net-tools转向使用iproute2。
iproute2是另外一个网络配置工具,致力于取代net-tools。和net-tools通过/proc文件系统和ioctl系统调用来访问和修改网络配置相比,iproute2是通过netlink套接字接口和内核进行通信的。一个大家都认同的观点是,使用netlink接口要比使用/proc文件系统轻盈。撇开性能不谈,iproute2工具比net-tools工具更加直观,更重要的是iproute2工具一直处于不断开发完善中。
关于iproute2和net-tools命令的使用对比,参加这篇文章。
traceroute
traceroute使用IPv4的TTL字段或者IPv6的跳限字段以及两种ICMP消息来确定IP数据报从本地主机游历到某个远程主机所经过的路径。它一开始向目的地发送一个TTL为 1的UDP数据报。这个数据报导致第一跳路由器返送一个ICMP”time exceeded in transmit”(传输中超时)错误。接着它每递增TTL一次发送一个UDP数据报,从而逐步确定吓一跳路由器。当某个UDP数据报到达最终目的地时,期望这个主机可以返送一个ICMP”port unreachabel”(端口不可达)错误。如何实现让目标主机返送这个错误呢? 一个简单但是不保证完全可行的方法是随机选取一个目的端口号向目标主机发送UDP数据报。
早期版本的traceroute程序只能通过设置IP_HDRINCL套接字选项直接构造自己的IPv4首部来设置TTL字段。然而如今的系统却提供IP_TTL套接字选项,它允许我们指定 发送出去的数据报用的TTL。实现的代码如下:
int ttl = 1;
int sendfd = socket(AF_INET, SOCK_DGRAM, 0);
setsockopt(sendfd, IPPROTO_IP, IP_TTL, &ttl, sizeof(int));
traceroute代码实现中比较复杂部分是解析收到的ICMP报文,traceroute中需要处理的ICMP报文格式如下:
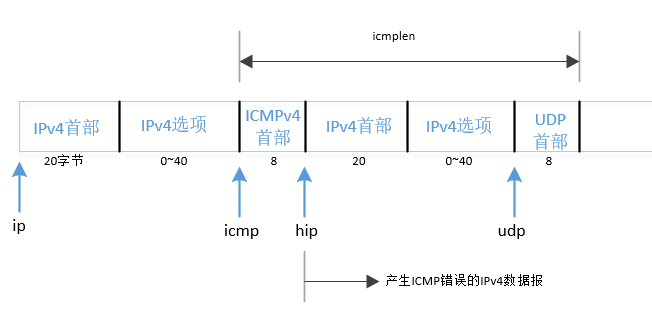
如果所读入的ICMP消息是一个”time exceeded in transmit”出错消息,那么它可能是响应本进程某个探测分组的应答。hip指向在这个ICMP消息中返回的IPv4首部。udp指向跟在这个IPv4首部之后的UDP首部。如果该ICMP消息是由某个UDP数据报引起的,而且这个UDP数据报的源端口和目的端口确实是本进程发送的值,那么它是来自某个中间路由器的响应我们的探测分组的一个应答。
如果所读入的ICMP消息是一个”destination unreachable”出错消息,我们就查看在这个ICMP消息中返回的UDP首部,判定它是不是响应本进程某个探测分组的应答。确认是的后,需要进一步判定这个ICMP的code字段是否为”port unreachable”。
ARP:地址解析协议
基础知识
地址解析协议(ARP)用于实现IP地址到网络接口硬件地址的映射,以太网(ether)是这里所说的网络中的一种。以太网48位的硬件地址就是我们常说的MAC地址。
在以太网中,当某个主机要向以太网中的另一台主机发送IP数据时,它首先根据目的主机的IP地址在ARP缓存(一个IP地址到相应以太网地址的映射表)中查询相应的以太网地址(MAC)。如果查询到匹配的结点,则相应的以太网地址被写入以太网帧首部,数据报被加入到输出队列等待发送;如果查询失败,ARP会先保留待发送的IP数据报,然后广播一个询问目的主机硬件地址的ARP报文,等收到回答后再将IP数据报发送出去。
运用
获取Gateway的MAC地址
执行arp -a获取当前的路由缓存信息,因为其中必定包含有Gateway的信息,所以可以通过这个命令获取Gateway的MAC地址。

netstat
今天在运行ffserver时出现Address already in use的错误提示,使用netstat工具去查看是哪个进程占用了端口号是一个不错的选择。现在记录一下netstat的一些用法。
| -a | 列出当前所有域的连接,包含TCP/IP域和UNIX域 |
| -tu | 只显示TCP/IP的连接信息 |
| -l | 只列出正在监听(LISTEN)状态的套接字 |
| -p | 查看连接所对应的进程名、进程号 |
| -e | 查看连接所对应的用户名 |
| -s | 列出所有网络包的统计情况 |
| -r | 显示内核路由信息 |
| -ie | 输出结果和ifconfig一致 |
| -g | 输出IPV4/V6的多播组信息 |
| -n | 禁用反向域名解析,加快查询速度 |
下面是使用带n和不带的对比:


网络IPC:套接字
SOCK_SEQPACKET 套接字类型和SOCK_RAW套接字类型很类似,但是该套接字得到的是基于报文的服务而不是字节流服务;SCTP(stream control transmission protocal)--流控制传输协议提供的就是因特网域上的顺序数据包服务。
SOCK_RAW套接字提供一个数据报接口用于直接访问下面的网络层(在因特网域中就是IP)。 使用这个接口时,应用程序负责构造自己的协议首部,这是因为传输协议(TCP、UDP)被绕开了。当创建一个原始套接字时需要有超级用户特权,用以防止恶意程序绕过安全机制。
tcpdump
tcpdump根据使用者的定义对网络上的数据包进行截获分析,它可以将网络中传送的数据包头完整截获下来提供分析。它支持针对网络层,协议,主机,网络或者端口的过滤。
filter example
- 通过标志位方法抓取 SYN 包:
tcpdump -i any 'tcp[tcpflags]&tcp-syn !=0'
Options
It’s important to note that tcpdump only takes the first 96 bytes of data from a packet by default.
| -n | names are not resolved,resulting in the IPs themselves always being displayed |
| -nn | don’t resolved hostnames or port names |
| -X | displays both hex and ascii content within the packet |
| -S | changes the display of sequence numbers to absolute rather than relative |
| -s | change the number of bytes you want to capture,and 0 means gets everything |
| -i eth0 | listen on the eth0 interface |
| -D | show the list of available interfaces |
| -v,-vv,-vvv | increase the amount of packet informaton you get back |
| -tttt | give maximally human-readable timestamp output |
| -c | only get x number of packets and then stop |
| icmp | only get ICMP packets |
有三个主要的types of expression: type,dir,and proto.
- Type options 主要包含:host,net,and port.
- Direction lets you do src,dst,and combinations thereof.
- Protocol 主要让你限定数据包所属的协议类型,必然tcp,udp,icmp,ah等等.
Basic Usage
如果想得到和wireshark软件中默认的抓包显示效果,可以执行:
#tcpdump -nnvS -s 0
如果比较关心数据包的时间值,可以添加-tttt,即执行:
#tcpdump -ttttnnvS -s 0
上面的-s 0表示不对抓取的数据量做限制,运行实际效果如下图。

如果想查看所抓包里面的具体二进制内容,可以添加-X选项,同时为了控制所抓包的数量,添加-c选项。下面就是从送往ip:172.8.1.98的数据包中抓取2个数据包进行内容查看。

Writing to a File
其实通常的情况是,我们在设备上通过tcpdump工具抓包保存到文件中,然后通过图形化的软件wireshark来分析数据。tcpdump保存的文件格式类型是PCAP.执行命令中添加-w选项即可。例如:
#tcpdump port 80 -w cap_file
Advanced
组合起各种选项设置可以实现非常强大的功能。实现组合的三种方式为:
-
AND – and or &&
-
OR – or or ||
-
EXCEPT – not or !
指定源ip和目的端口
#tcpdump -nnvvS src 172.8.1.98 and dst port 37777
查看所有192.168.x.x网段内到10.x网段或者到172.16.x.x网段的数据包
#tcpdump -nvX src net 192.168.0.0/16 and dst net 10.0.0.0/8 or 172.16.0.0/16
过滤掉发往某个ip的icmp数据包
#tcpdump dst 192.168.0.2 and src net and not icmp
当我们使用更加复杂的过滤选项时,有时我们需要使用单引号来规避特殊符号的干扰
例如#tcpdump src 10.0.2.4 and (dst port 3389 or 22)这样的写法是错误的,应该是#tcpdump 'src 10.0.2.4 and (dst port 3389 or 22)'

下面借助上图介绍如何通过TCP FLAGS来进行过滤。
过滤出所有URG packets
#tcpdump 'tcp[13]&32 !=0'
过滤出所有ACK packets
#tcpdump 'tcp[13]&16 != 0'
过滤出所有RST packets
#tcpdump 'tcp[13]&8 != 0'
过滤出所有SYNACK(SYNCHRONIZE/ACKNOWLEDGE) packets
#tcpdump 'tcp[13]=18'
下面介绍几个需要死记但是非常实用的过滤条件
packets with both the RST and SYN flags set
#tcpdump 'tcp[13]=6'
find cleartext http GET requests
#tcpdump 'tcp[32:4]=0x47455420'
find SSH connections on any port(via banner text)
#tcpdump 'tcp[(tcp[12]>>2):4] = 0x5353482d'
find packets with a TTL less than 10(usually indicates a problem or use of TRACEROUTE)
#tcpdump 'ip[8]<10'
wireshark
实战操作
计算Out-of-order报文的比例
-
计算全部报文数量:capinfos file.pcap grep packets - 计算乱序报文数量:tshark -n -q -r file.pcap -z “io,stat,0,tcp.analysis.out_of_order”
设置数据抓取选项
点击常用按钮中的设置按钮,就会弹出如下图所示的选项对话框:
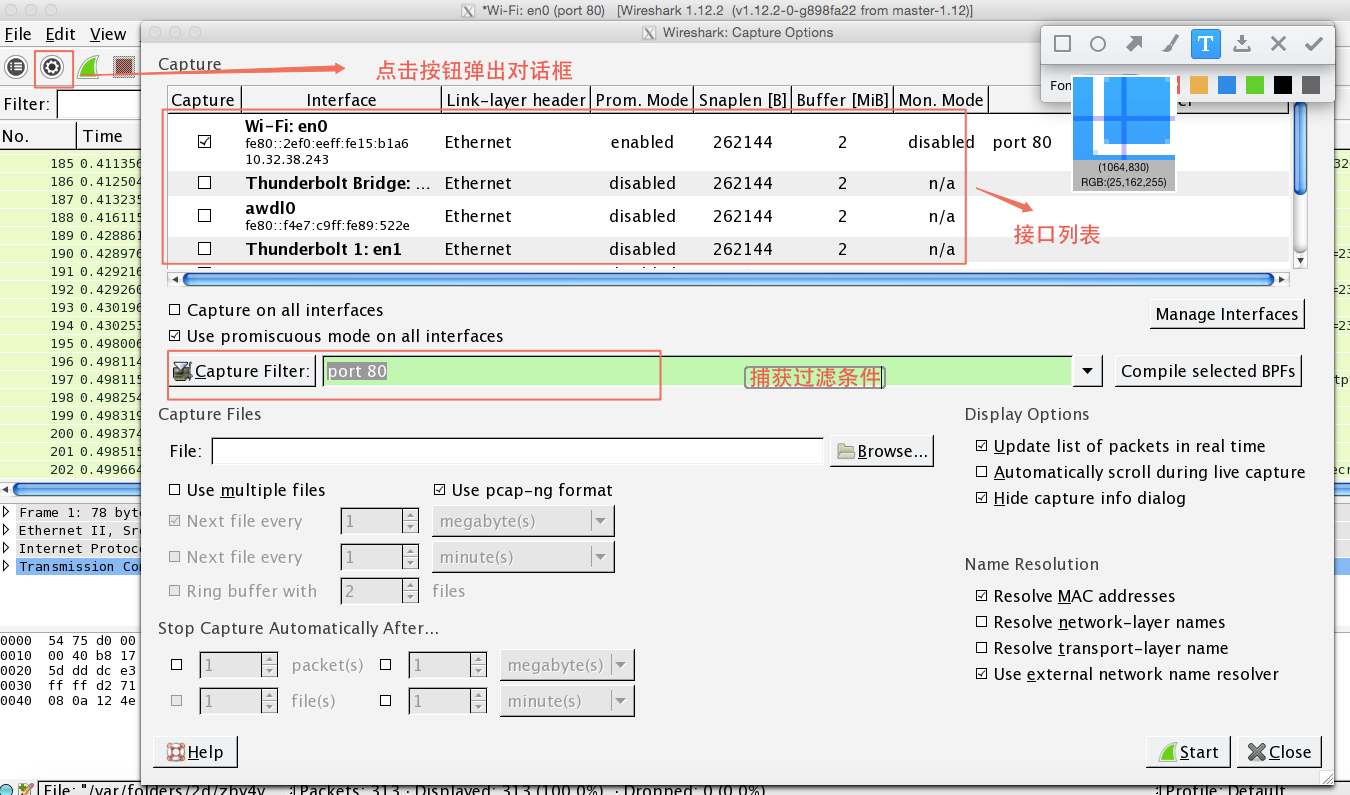
这里面主要有两个设置,一个是设置混杂模式(promiscuous mode),使能该模式就可以捕获局域网内所有的数据包,否则你只能捕获发往你主机或者从你主机出去的数据包。
另一个设置项是捕获过滤条件(capture filter),注意它不同于后面将要提到的显示过滤条件。如果我们只想捕获http相关的数据包,我们就可以设置捕获过滤条件为”port 80”
使用显示过滤器
在Filter对话框里面可以直接填写过滤条件,常见的如指定只想查看某个ip过来的所有数据包,如下图所示:

我们同时限定了源ip和目的ip。另外,当我们想将我们过滤好的数据包生成新的抓包文件时,如下图所示,点击Export special pakcts as...,进行保存即可。

点击显示表达式按钮(Expression),对应对话框如下:
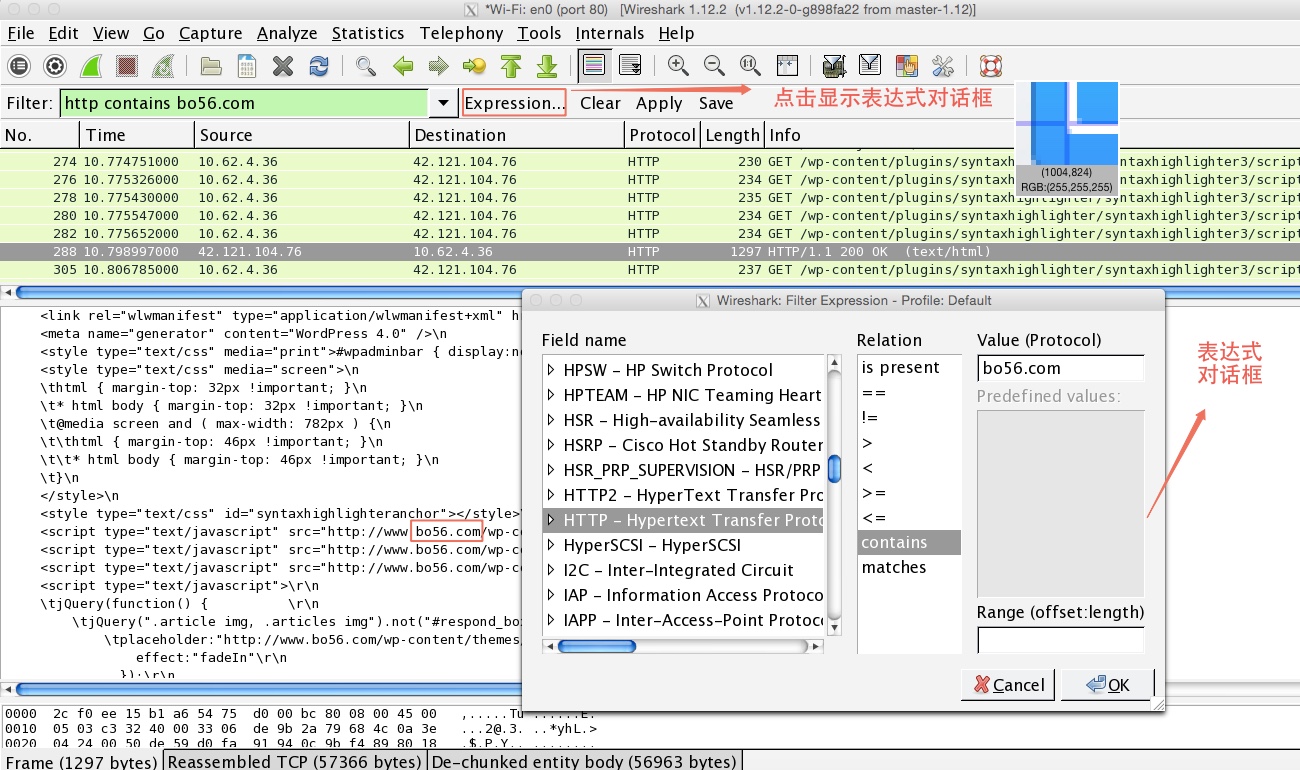
对话框中分为协议域(field name),关系(relation),条件值(value),预定义值(predefined value)。 如上图,我们创建的表达式的作用是,只显示http协议包中包含关键字”bo56.com”的所有数据包。
Field name说明
这个列表展示了所有支持的协议。点击前面的三角形标志后,可以列出本协议的可过滤字段。 直接找需要的协议可能比较麻烦,可以输入协议中开头字符进行自动模糊查询自动跳转。
Relation说明
| is present | 如果选择的协议域存在,则显示相关数据包 |
| contains | 判断一个协议,字段或者分片包含一个值 |
| matchs | 判断一个协议或者字符串匹配一个给定的perl表达式 |
Predefined values说明
有些协议域包含了预定义的值,有点类似c语言中的枚举类型,如果你选择的协议域包含这样的值,你可以在这个列表中选择。
Function函数说明
过滤器的语言还有下面几个函数:
upper(string-field) - 把字符串转换为大写 lower(string-field) - 把字符串转换为小写
例如:
upper(ncp.nds_stream_name) contains “BO56.COM” lower(mount.dump.hostnmae) == “BO56.COM”
使用着色规则
点击”view”菜单,然后选择”coloring rules”选项就会弹出设置颜色规则设置对话框,如下图:
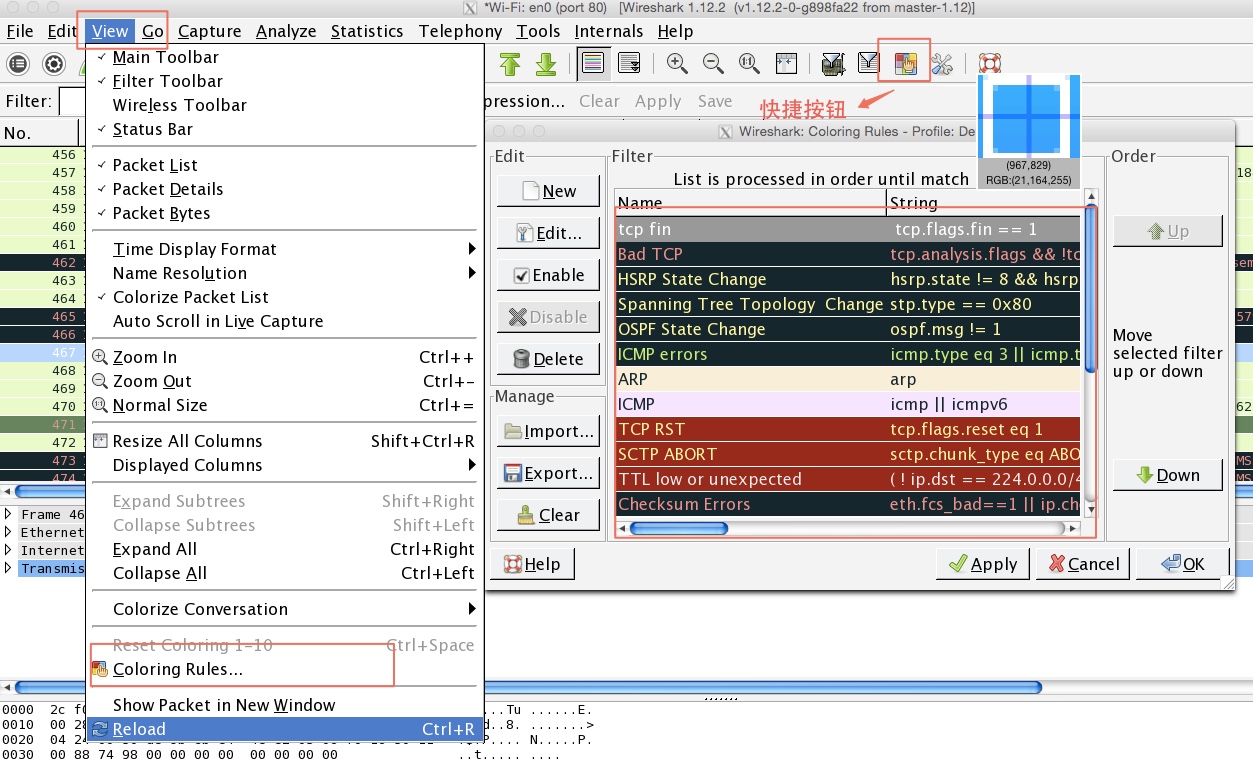
对话框已经包含了很多已经存在的规则,如果要新建则点击”New”,弹出对话框如下:
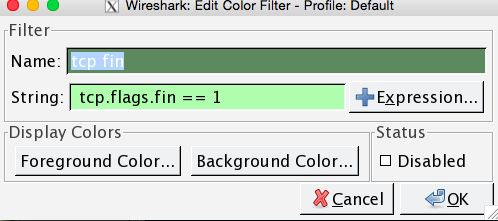
name字段中填写规则名称,方便记忆。
string字段填写过滤规则,这里的语法和显示规则表达式一致。
注意:wireshark在应用规则的时候,是自上而下的顺序去应用规则,因此刚添加的规则会优先应用。如果想调整顺序,可以选中规则,然后点击右边的”UP”和”Down”按钮。
跟踪tcp流
这个功能是将接收到的数据排好顺序使之容易查看,而不需要一小块一小块地查看。这在查看http,ftp等纯文本应用层协议时非常有用的。
使用方法就是对所获取数据包感兴趣的条目中执行右击,然后选择跟踪跟踪流(Follow TCP Stream)。具体可以参照以下两张图:
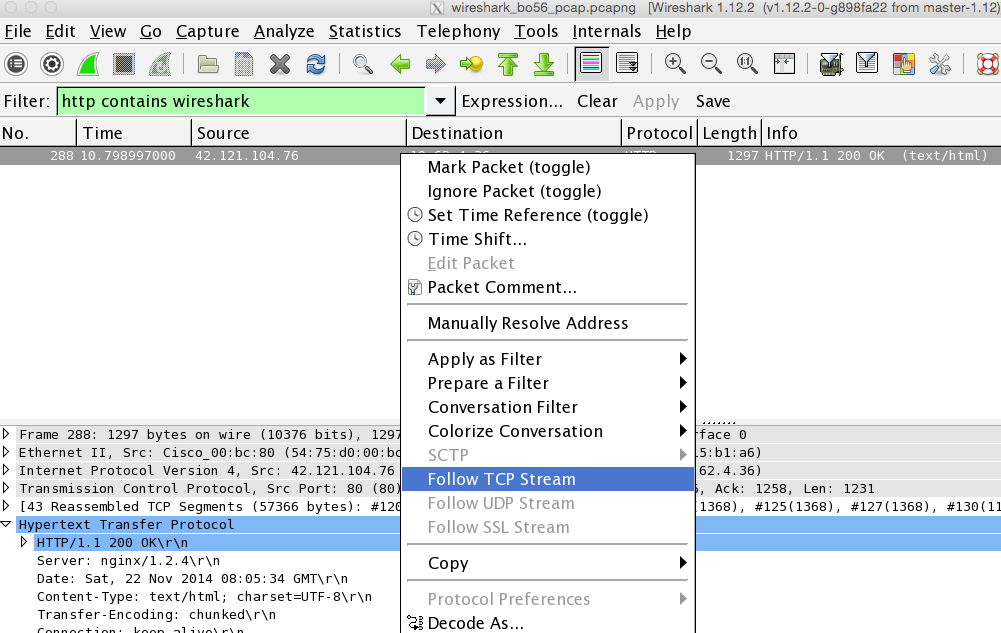
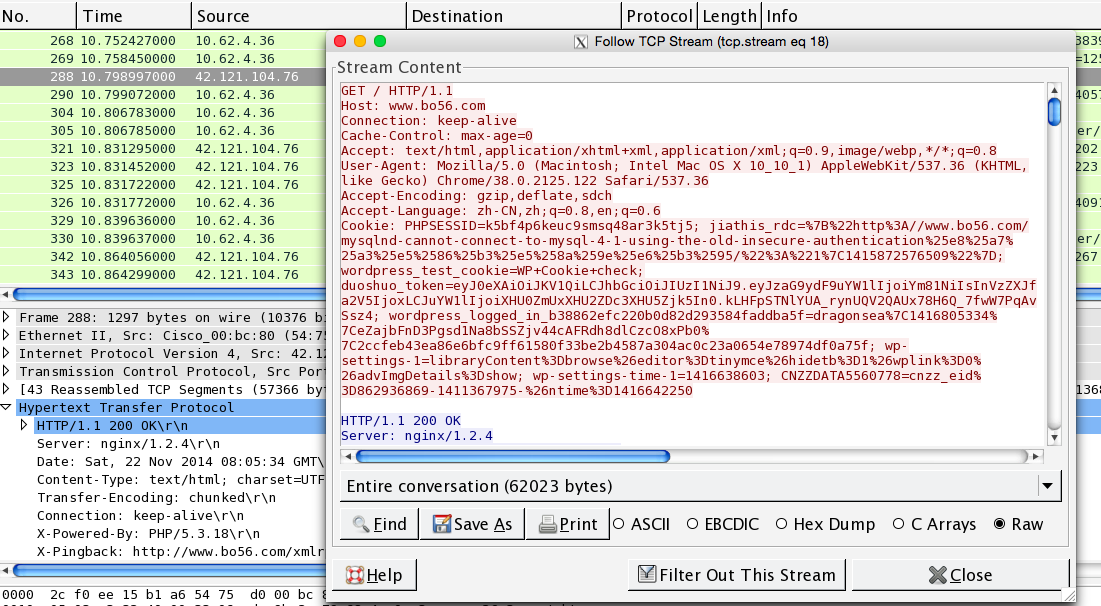
上图中底部有个下拉框,默认是如图的Entire conversation,即上面的stream content是tcp两端对话的往返流,有时我们只需要分析单向的流数据,如下图,这时可以点击下拉框,选择我们想指定的一个数据流向。

图形化显示
跟踪好tcp流之后,关掉弹出窗口,点击statistcs -> Flow graph生成图形化显示,同时勾选左下角的limit to display filter已经选择中间栏中的TCP Flow就可以显示所跟踪的tcp连接的图形化了。
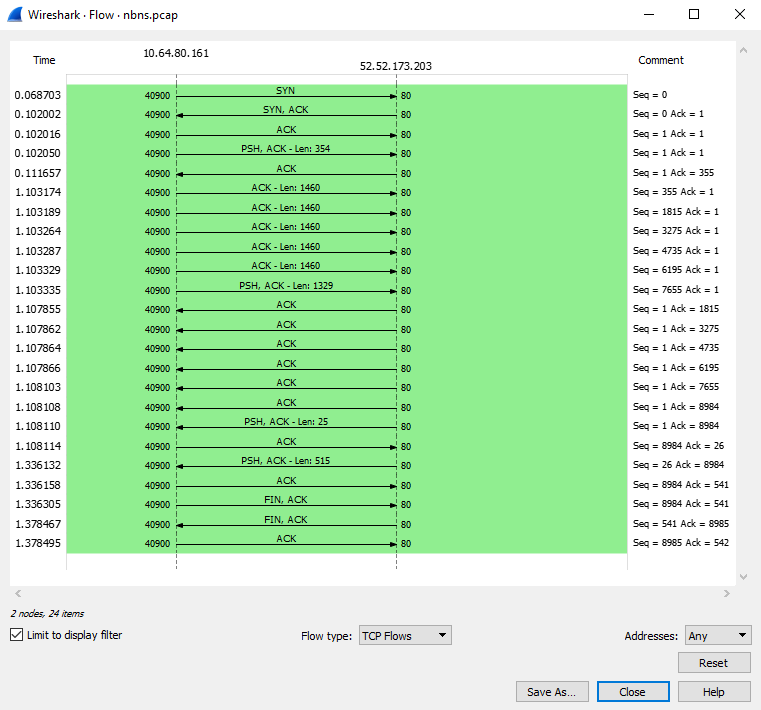
跟踪tcp回话过程
在定位某个基于tcp的协议功能问题时,使用tcp回话跟踪功能可以很方便直接的定位到问题点,比如根据谁发送了FIN RST来判断是服务端问题还是客户端问题。
启用这个功能按如下步骤:
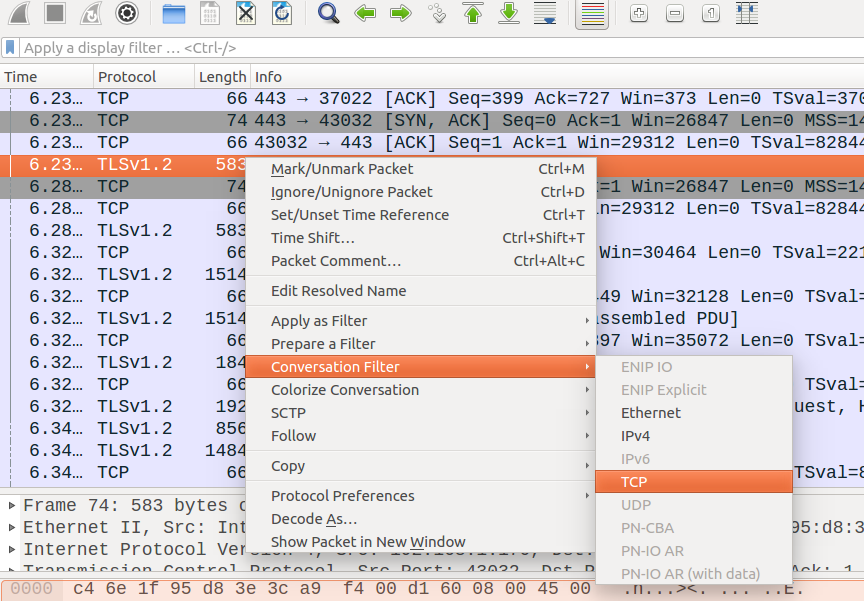
搜索想要的数据包
-
frame contains "mozilla"- 在数据报内所有地方搜索包含mozilla字样的字符串 -
dns.resp.len > 0- 搜索所有DNS的回应包 -
ip.addr == 52.7.23.87- 搜索源ip或者目的ip是52.7.23.87的包,当然也可以通过ip.dst == xxx或者ip.src == xxx来更加精确的搜索。 -
ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1