记录开发中实际涉及的Linux应用编程知识
信号
basic
- 除非调用exec的进程将某些信号设置为SIGIGN, 否则exec会将原先设置为捕捉的信号都更改为信号的默认动作,原因是在新的进程中,原来的信号处理函数地址变得无效。所以在fork()后,子进程中调用exec后,子进程的所有信号除了之前被忽略的,其他都会恢复到默认动作。
SIGCHLD
-
使用sigaction函数可以捕捉发送SIGCHLD的进程pid
#include
int sigaction(int signo, const struct sigaction *restrict act, struct sigaction *restrict oact);
struct sigaction{ void (sa_handler)(int); sigset_t sa_mask; int sa_flags; void (sa_sigaction)(int, siginfo_t *, void *); };
当将sa_flags设置为SA_SIGINFO时,信号处理会调用sa_sigaction字段的函数。
struct siginfo{
int si_signo;
...
pid_t si_pid;
uid_t si_uid;
...
int si_status;
...
};
如果信号时SIGCHLD,则将设置si_pid,si_status和si_uid字段。
用户管理
添加user并添加sudo权限
$ sudo useradd new_user
$ sudo usermod -aG new_user sudo
GCC编译选项
LDFLAGS=-Wl,--gc-sectionsCFLAGS=-ffunction-sections-ffdata-sections
在链接第三方库时,由于其存在很多功能代码和变量在本项目中可能用不到,所以为了节省内存,可以在编译阶段指定-ffunction-sections和-ffdata-sections,在链接阶段指定--gc-sections来实现程序在链接阶段指包含必要的第三方代码和变量。
该功能需要GCC版本大于4.8。
LDFLAGS += -Wl,-rpath,'$$ORIGIN/../lib'
-rpath和-L都是指定动态链接的搜索位置,-L在编译阶段指示ld链接器搜索链接库的位置,-rpath是在程序运行阶段指定链接库搜索位置。一般情况下ELF会放置在bin目录下,链接库会放置在lib目录下,所以为了程序部署到不同环境下保持兼容性,使用$ORIGIN变量代表程序的安装目录,在运行时,$ORIGIN被替换为安装路径。
-fPIC/-fPIE
PIC用于生成位置无关的动态链接库,而PIE用于生产位置无关的ELF。
-fstack-protector/-fstack-protector-all
stack overflow是c语言常见而有致命的问题,漏洞攻击往往都是利用stack overflow后注入非法代码,为了及时检测到stack被篡改的情况,gcc提供了上面两个选项。其基本思想都是在stack中push完一个返回值后,立马再push一个随机整数,而当pop返回值时会检测该随机数,如果发现不相等,就abort程序。 因为实现这样的保护措施会有额外的性能损失,所以gcc提供了上面两个选项,前者只在stack上申请了8个字节以上的数组的函数编译时才会加上这个机制,而后者对所有函数都使用这个保护机制。更详细说明参考链接
正则表达式
基本语法
正则表达式涉及到符号很多,乍看非常混乱,所以一个比较好的学习方法是先给涉及到的所有符号进行分类归纳。
描述位置的符号 - ^ $
^表示以什么开头
$表示以什么结尾
描述数量的符号 - * + ? {}
*表示任意多个,包括0
+表示任意多于0个
?表示0或者一个
{}表示个数范围
值得注意的是,这里我们没有讨论
.,因为.没有数量的属性,只是表示一个任意字符,具体后面有归纳。
另外,*表示任意多个,没有说表示任意多个字符,这是有很大区别的,比如:
abc* matches a string that has ab followed by 0个或者多个c
而
a(bc)* matches a string that has a followed by 0个或者多个bc
类似的:
abc+ matches a string that has ab followed by 一个或者多个c
abc? matches a string that has ab followed by 0个或者一个c
abc{2} matches a string that has ab followed by 2个c
abc{2,} matches a string that has ab followed by 2个或者多个c
abc{2,5} matches a string that has ab followed by 2到5个c
描述字符类型的符号
\d matches 一个数字
\w matches 一个字母,包括下划线
\s matches a whitespace character includes tabs and line breaks
. matches any character
比如,现在需要从下面两个字符串中提取类似的信息,
<wsdisco:Types>wsdp:Device wprt:PrintDeviceType wscn:ScanDeviceType</wsdisco:Types>
<d:Types>dn:NetworkVideoTransmitter</d:Types>
我们想从上面两个字符串中提取types信息,怎么写正则表达式呢?
假设我们是用python,那么正则如下:
r'<\w+:Types>\w+:(.+?)</\w:Types>'
上面三处出现的\w+就是匹配掉wsdisco和d,wsdp和dn的差异的。
另外值得注意的是,因为\w只能匹配字母,如果上面最后一处的\w前面的/不加的话,就会出现匹配不对的问题。
掌握上面两种基本符号的用法后,我们要学会组合使用它们,比如
.*就可以表示任意的字符。
特殊符号 - []、()
()作用是Grouping和Capturing,对于用于从字符串中提取关键信息非常有用。具体实例可以参见下面章节的内容。
[]主要是匹配多个范围,需要特别注意的是所有的特殊符号在[]都失去原来的作用,比如backslash\不在具有escape的功能,^已不是代表匹配开头,而是used as negation of the expression。
wsdd协议中的response是一个xml描述的“信封”,假设现在我们要提取xml中<a:MessageID>urn:uuid:xxx</a:MessageID>这个elemnt中的uuid信息。因为elemnt的key可能是<xxx:MessageID>,所以匹配的正则稍微复杂一点:
<[^:]*:MessageID>urn:uuid:([^<]*)</[^:]*:MessageID>
上面这个例子很好的诠释了[]和()组合使用的强大功能。[]加上^负责过滤掉无用信息,()负责提取有用信息。
进阶
Greedy and Lazy match
*、+、{}这几个描述数量的符号是greedy operators, so they expand the match as far as they can through the provided text.
比如,有这么一个字符串:
This is a <div>simple div</div> test.
我们想过滤掉所有<>及其中内容,如果使用正则表达式<.+>,那么发现匹配到的是<div>simple div</div>,也就是匹配了第一个<和最后一个>,
显然不是我们希望的。
为了匹配<>tag, 我们可以借助添加?使其变得lazy,也就是使用<.+?>去过滤,结果就是正确的This is a simple div test.
动态链接相关的
这部分内容主要阐述Linux环境下动态链接的一些环境参数和编译链接的参数选项的使用,主要涉及到LD_LIBRARY_PATH、LD_PRELOAD、LD_DEBUG这几个环境变量,-rpath链接选项,-L、-l编译选项。这些知识点在网上有很多,但是大部分都是说得不够清楚详细。
首先这些环境变量和编译链接选项总的可以分为两类,一类就是控制编译阶段行为,另一类就是控制链接装载时的行为。注意这里说的是链接装载,区别于静态链接。
下面就一个实际的实例来阐述这些环境变量和编译链接参数的作用。在嵌入式软件开发里,一般程序在编译服务器上编译,然后放到目标机上进行运行。这样就导致经常出现的一个情况就是,编译时指定的参与编译的动态库查找目录和最终在实际目标机上的文件系统上的动态库链接装载查找目录对应不上。
unix中的时间值
unix系统中使用两种不同的时间值,日历时间和进程时间。
日历时间
日历时间很好理解,其实就是和程序没有任何关系的自然时间。该值是自1970年01.01.00:00:00以来的国际标准时间(UTC)。见到最多的地方应该是我们执行ls -l时,文件和文件夹后面跟着的时间值。这是因为unix系统就是使用这些时间值来记录文件最近一此被修改的时间等。
系统基本数据类型time_t用于保存这种时间值。time函数返回当前时间和日期:
#include <time.h>
time_t time(time_t *calptr);
clock_gettime()函数可用于获取指定时钟类型的时间,它把时间表示为秒和纳秒:
#include <sys/time.h>
int clock_gettime(clockid_t clock_id, struct timespec *tsp);
时钟类型通过clockid_t类型来标识:
| 标识符 | 选项 | 说明 |
|---|---|---|
| CLOCK_REALTIME | / | 实时系统时间 |
| CLOCK_MONOTONIC | _POSIX_MONOTONIC_CLOCK | 不带负数的实时系统时间 |
| CLOCK_PROCESS_CPUTIME_ID | _POSIX_CPUTIME | 调用进程的CPU时间 |
| CLOCK_THREAD_CPUTIME_ID | _POSIX_THREAD_CPUTIME | 调用线程的CPU时间 |
进程时间
该时间主要是用来度量进程使用cpu资源情况的,所以又被称之为cpu时间。系统使用基本数据架构clock_t来保存这种时间值。任一进程都可以调用times函数来获得它
自己以及终止进程的墙上时钟时间、用户CPU时间和系统CPU时间。
#include <sys/times.h>
struct tms{
clock_t tms_utime; /*user CPU time*/
clock_t tms_stime; /*systme CPU time*/
clock_t tms_cutime; /*user CPU time, terminated children*/
clock_t tms_cstime; /*systme CPU time, terminated children*/
};
clock_t times(struct tms *buf);
有时,我们只想获取一个程序消耗的墙上时钟时间,可以使用clock()函数:
#include <time.h>
clock_t clock(void);
需要注意的是,上面所有clock_t的时间值,都要_SC_CLK_TCK(由sysconf函数返回的每秒时钟滴答数)转换成秒数。
存储映射I/O(mmap)
基本概念
存储映射I/O使一个磁盘文件与存储空间的一个缓冲区相映射,这样就不用执行read和write 来读文件或者写缓存区。
为了使用这种功能,应首先告诉内核将一个给定的文件映射到一个存储区域中。这是由mmap函数实现的。
#include <sys/mman.h>
void *mmap(void *addr, size_t len, int prot, int flag, int fd, off_t off);
addr参数
用于指定映射存储区的起始地址,通常设置为0,这样表示由系统选择该映射区的起始地址。此函数的返回地址是该映射区的起始地址。
prot参数
说明对映射区的保护要求:
| prot | 说明 |
|---|---|
| PROT_READ | 映射区可读 |
| PROT_WRITE | 映射区可写 |
| PROT_EXEC | 映射区可执行 |
| PROT_NONE | 映射区不可访问 |
对指定映射存储区的保护要求不能超过文件open模式访问权限。
flag参数
影响映射存储区的多种属性:
| flag | 说明 |
|---|---|
| MAP_FIXED | 返回值必须等于addr.如果未指定此标志,而且addr非0,则内核只把addr视为在何处设置映射区的一种建议。 |
| MAP_SHARED | 此标志指定存储操作修改映射文M件,也就是说,存储操作相当于对该文件的write。 |
| MAP_PRIVATE | 此标志说明,对映射区的存储操作导致创建该映射文件的一个私有副本。 |
| MAP_XXX | 各个不同系统定义自己支持的flag,具体参考mmap(2) |
off 和 addr的值通常应该是系统虚存页长度的倍数。虚存页的长可用带参数_SC_PAGESIZE或者_SC_PAGE_SIZE的sysconf函数得到。
与映射存储区相关的信号有SIGSEGV和SIGBUS。前者通常用于指示进程试图访问对它不可用的存储区。另外,如果进程企图存储数据到mmap指定为只读的映射存储区, 那么也产生此信号。
如果访问映射区的某个部分,而在访问时这一部分实际上已不存在,则产生SIGBUS信号。例如,某个进程截短了另一个进程映射的文件,此时如果这个进程访问已截去的映射区, 则会收到SIGBUS信号。
进程终止时,或者调用了munmap之后,存储映射区就被自动解除映射。但是关闭文件描述符并不解除映射区。
下面是mmap与使用read/write(缓冲区长度为8196)进行文件复制性能的比较,被复制文件的长度是300MB:
read/write 与 mmap/memcpy比较的时间结果
| 操 | Linux2.4.22(intel x86) | ||
|---|---|---|---|
| 作 | 用户 | 系统 | 时钟 |
| read/wirte | 0.04 | 1.02 | 39.76 |
| mmap/memcpy | 0.64 | 1.31 | 24.26 |
如果考虑到时钟时间,那么mmap和memcpy方式比read/write方式要快。
实例分析
内核中的运用
alsa中,应用空间和内核空间分别维护着ring buffer的读写指针,这个ring buffer是用来缓存播放数据或者是采集数据的。为了保证ring buffer的 状态信息在应用层和内核层的同步性,alsa-lib通过mmap将驱动中的变量之间映射到用户空间进行操作。
/**
* alsa-lib/src/pcm/pcm_hw.c
*/
enum{
SNDRV_PCM_MMAP_OFFSET_DATA = 0X00000000,
SNDRV_PCM_MMAP_OFFSET_STATUS = 0X80000000,
SNDRV_PCM_MMAP_OFFSET_CONTROL = 0X81000000,
};
static int snd_pcm_hw_mmap_status(snd_pcm_t *pcm)
{
snd_pcm_hw_t *hw = pcm->private_data;
void *ptr;
ptr = mmap(NULL, page_align(sizeof(struct snd_pcm_mmap_status)),
PROT_READ, MAP_FILE|MAP_SHARED,
hw->fd, SNDRV_PCM_MMAP_OFFSET_STATUS);
...
return 0;
}
static int snd_pcm_hw_mmap_control(snd_pcm_t *pcm)
{
snd_pcm_hw_t *hw = pcm->private_data;
void *ptr;
ptr = mmap(NULL, page_align(sizeof(struct snd_pcm_mmap_control)),
PPOT_READ|PROT_WRITE, MAP_FILE|MAP_SHARED,
hw->fd, SNDRV_PCM_MMAP_OFFSET_CONTROL);
...
return 0;
}
上面代码中值得注意的地方是第二个入参使用page_align进行了page对齐操作,以及最后一个入参off的定义。
自己编写实例运用
下面我们自己实现一个驱动和一个应用程序,完整的展现一下mmap的运用。首先在驱动程序中分配一页大小的内存,然后应用程序通过mmap将这块内存映射进用户空间。映射完成后,驱动程序往这块内存填写一些数据,然后应用进程打印出这些数据。
驱动程序:
/**
* saiyn_driver.c
*/
#include <linux/miscdevice.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/mm.h>
#include <linux/fs.h>
#include <linux/types.h>
#include <linux/errno.h>
#include <linux/ioctl.h>
#include <linux/cdev.h>
#include <linux/string.h>
#define DEVICE_NAME "saiyn_mmap"
static unsigned char *buf;
static int saiyn_mmap(struct file *filp, struct vm_area_struct *vma)
{
unsigned long page;
long size = vma->end - vma->start;
page = virt_to_phys(buf);
if(remap_pfn_range(vma, vma->start, page >> PAGE_SHIFT, size, PAGE_SHARED))
{
printk("remap_pfn_range fail.\n");
return -1;
}
strcpy(buf, "saiyn mmap");
return 0;
}
static struct file_operations dev_fops = {
.owner = THIS_MODULE,
.open = saiyn_open,
.mmap = saiyn_mmap,
};
static struct miscdevice misc = {
.minor = MISC_DYNAMIC_MINOR,
.name = DEVICE_NAME,
.fops = &dev_fops,
};
static int __init dev_init(void)
{
int ret;
ret = misc_register(&misc);
buf = (unsigned char *)kmalloc(PAGE_SIZE, GFP_KERNEL);
/**
* 将该段内存设置为保留
*/
SetPageReserved(virt_to_page(buf));
return ret;
}
static void __exit dev_exit(void)
{
misc_deregister(&misc);
ClearPageReserved(virt_to_page(buf));
kfree(buf);
}
module_init(dev_init);
module_exit(dev_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("saiyn");
应用程序:
/**
* saiyn.c
*/
#define _GNU_SOURCE
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <errno.h>
#define PAGE_SIZE (sysconf(_SC_PAGE_SIZE))
int main()
{
int fd;
unsigned char *buf;
fd = open(/dev/saiyn_mmap, O_RDWR);
if(fd < 0)
{
printf("open saiy_mmap device fail: %d - %s\n", errno, strerror(errno));
return -1;
}
buf = (unsigned char *)mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if(buf == MAP_FAILED)
{
printf("mmap fail: %d - %s\n", errno, strerror(errno));
return -1;
}
printf("buf:%s\n");
munmap(buf, PAGE_SIZE);
return 0;
}
匿名存储映射
在调用mmap时指定MAP_ANONYMOUS标志,并将文件描述符fd指定为-1,偏移量off设为0,就可以得到一个匿名的区域(因为它并不通过一个文件描述符与一个路径相结合),并且创建一个可与后代进程共享的存储区。具体的调用方法如下:
area = mmap(0,SIZE,PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_SHARED, -1, 0);
因为mmap并不是分配实际的物理内存,而只是占用进程中的virtual memory,即虚拟地址空间。所谓”只是占用”是指,当我们通过mmap从虚拟内存空间中申请内存时,操作系统并不会从物理内存中申请相同大小的物理内存,而是当我们实际操作了多大内存时,系统才会从物理内存中拿出多大的内存。
这样,我们可以通过匿名存储映射实现我们的虚拟内存分配函数virtual_malloc(),使用它做一些非常trick的事情。
创建超大数组
在实际项目中我们经常会碰到这样的寻求,我们需要一个数组来做映射表,有时键值是不连续的整形,而且有的会很大。这时我们会”痛苦”地发现,直接通过 int array[MAX_SIZE]使用静态内存,还是 int *array = malloc(MAX_SIZE)动态申请内存,都不太合适,因为我们机器的内存还是很紧俏的,不太可能随随便便申请百兆甚至上G的内存。通过使用匿名存储映射实现我们的虚拟内存分配函数可以巧妙的解决我们的烦恼。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#include <errno.h>
#include <string.h>
#define MAX_OBJECTS (1000000000ULL)
#define PAGE_SIZE sysconf(_SC_PAGE_SIZE)
static void *virtual_alloc(size_t size)
{
void *ptr;
ptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1,0);
return ptr;
}
int main()
{
int *array = virtual_alloc(MAX_OBJECTS * sizeof(int));
if(!array)
{
printf("virtual_alloc fail, %d - %s\n", errno, strerror(errno));
return -1;
}
array[100000] = 12345678;
printf("value: %d\n", array[100000]);
return 0;
}
编译执行代码,发现在只有2G内存的机器上也是正常运行的,而我们上面分配的虚拟内存为8G,这就证明了mmap只是从虚拟内存中申请地址空间。目前的处理器基本上都是64位的了,理论上虚拟地址空间总共2的64次方大小,虽然实际上目前的硬件只实现了48位地址线,那也是256TB的空间,足够大了。
优雅实现RingBuffer
具体参见这篇文章
更多关于virtual memory的tricks见这篇文章
Linux启动
启动具体流程
- 加载BIOS执行硬件自检,依据设置取得第一个可启动设备。
- 读取并执行第一个启动设备内MBR的boot loader。MBR位于第一个扇区,也就是最前面512字节。主引导记录有三部分组成:
- 第1-446字节:调用操作系统的机器码
第447-510字节:分区表(Partition table)
分区表只有64个字节,里面分成四项,形成四个主分区,每项16个字节,由6个部分组成:
* 第一个字节:如果为0x80,就表示该主分区是激活分区,控制权要转交给这个分区。 * 第2-4个字节:主分区第一个扇区的物理地址。 * 第5个字节: 主分区类型。 * 第6-8个字节:主分区最后一个扇区的物理地址。 * 第9-12字节:该主分区第一个扇区的逻辑地址。 * 第13-16字节:主分区的扇区总数。- 第511-512字节:主引导记录签名(0x55,0xAA)
- 加载内核镜像。
- kernel主动调用init进程,而init进程会取得run-level信息。
- init执行/etc/rc.d/rc.sysinit文件来准备软件执行的操作环境。
- init执行run-level的各个服务启动(script方式)。
- init执行/etc/rc.d/rc.local文件。
- init执行终端模拟程序mingetty来启动login进程。
启动相关细节
1.由于模块放置在磁盘的根目录内,因此在启动的过程中内核必须要挂载根目录系统,而且为了担心影响到磁盘内的文件系统,因此启动过程中根目录是以只读方式来挂载的。
2.虚拟文件系统(InitialRAM Disk)一般使用的文件名为/boot/initrd,这个文件的特色是,它也能够通过boot loader来加载到内存中,然后这个文件会解压到内存中仿真成一个根目录,且该仿真文件系统能够提供一个可执行程序来加载启动过程中最需要的内核模块。
3.需要initrd最重要的原因是,当启动时无法挂载根目录的情况下,此时就一定要initrd。如果你的linux是安装在IDE接口的磁盘上,并且使用默认的ext2/3文件系统时,那么没有initrd也能顺利启动linux。
4.在内核加载完成后,你的主机应该开始正确运行了,接下来,就是要开始执行系统的第一个程序:/sbin/init。
5.pid为1的/sbin/init程序通过/etc/inittab配置文件来规划,/etc/inittab文件内有一个很重要的设置选项,那就是默认的run level(启动执行等级)。
6.inittab中的语法是:[设置选项]:[run levle]:[init的操作行为]:[命令选项].
init的操作行为说明如下表:
| inittab设置值 | 意义说明 |
|---|---|
| initdefault | 代表默认的runlevel设置值 |
| sysinit | 代表系统初始化的操作选项 |
| wait | 代表后面字段设置的命令项目必须要执行完毕才能继续下面其他的操作 |
| respawn | 代表后面的字段设置的命令可以重新启动 |
启动系统服务与相关启动配置文件
1.服务的启动是/etc/rc.d/rc文件以/etc/init.d/xxx{start,stop}来启动与关闭的。
2./etc/rc.d/ 中的文件都是K和S开头的文件,后面接着的数字是表示该文件被执行的顺序,数字越大表示越后执行。
3.最后一个被执行的选项是S99local,即是/etc/rc.d/rc.local这个文件。
用户自定义启动程序(/etc/rc.d/rc.local)
我们有任何想要在启动时就可以进行的工作,直接将它写入/etc/rc.d/rc.local就会在启动时候被自动加载。而 不必等我们登陆系统去启动它。
启动过程中会用到的主要配置文件
1.启动过程中用到的配置文件大多数放置在/etc/sysconfig目录下。
2.某些条件下我们得对模块进行一些参数的规划,此时要使用/etc/modprobe.conf。
基本命令的使用
awk/sed
掌握这两个上古神器是很重要的,下面从使用awk/sed解决实际问题出发来介绍两个神器的使用技巧。
使用文件过滤文件
今天遇到这么一个需求,两个文件记录了一些IP地址,其中一个文件是另外一个文件的乱序“子集”,如下图所示,tmp2文件中包含tmp文件中的所有IP,同时也有新增加的。


现在我想知道,tmp2文件中的哪些IP是新增的。使用awk的内建变量和数组可以快速实现这个需求。
执行awk 'FILENAME=="tmp" {a[$2]=$2} FILENAME=="tmp2" {if(!a[$2]{print $2})}' tmp tmp2,得到结果如下:

FILENAME是awk的内建变量,表示的是当前正在出来的文件名。
awk中的数组其实和c++中的map类似,运用好,很强大。
截取文本中的一个段落
如下图是xrandr的结果输出,我们的需求是获取某个端口支持的分辨率信息,也就是谁我们需要截取这个输出中的一个段落。
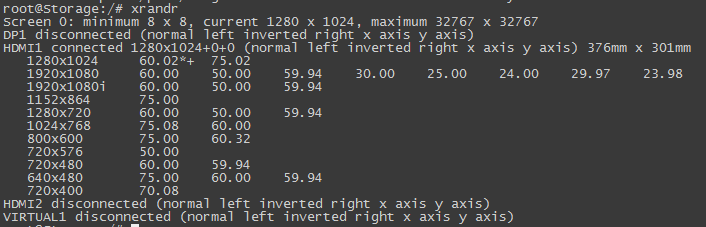
awk对于按列处理文本流很好使,但是对于按行截取一个段落好像有点力不从心,所以需要结合awk和sed一起完成需求功能。
因为分辨率信息都在同一列,使用awk提取出第一列,执行xrandr | awk '{print $1}',结果如下:
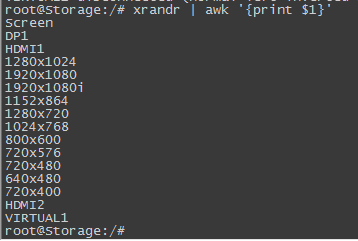
然后在上面的基础上再使用sed截取HDMI1和HDMI2之间部分的分辨率信息,执行xrandr | awk '{print $1}' | sed -n "/^HDMI1/,/^HDMI2/p",结果如下:
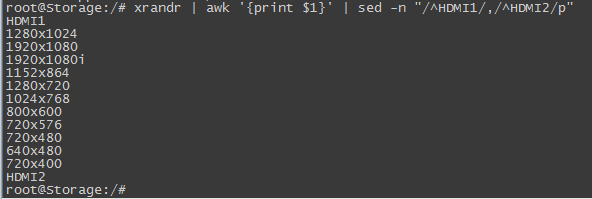
提取字符串中的片段
在分析shodan数据时,想从其所有upnp协议数据中提取出Location:字段的IP地址,分析看看是否存在可直接访问的location地址。
下面是一条upnp协议包含的部分数据:
Server: Custom/1.0 UPnP/1.0 Proc/Ver\r\nEXT:\r\nLocation: http://109.164.198.137:5431/dyndev/uuid:c86c8777-684b-4b68-7787-6cc86c774b00\r\nCache-Control:max-age=1800\r\n
我们的目标是提取http://109.164.198.137出来,使用的命令如下:
sed 's/.*\(http:\/\/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\).*/\1/' upnp.json | grep ^http | sort | uniq > upnp_location_ip
结果为:http://109.164.198.137
其中,sed 's/.*\(http:\/\/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\).*/\1/' upnp.json就是从upnp.json文件中提取location地址,为了过滤掉不符合其正则规则的记录,后面使用grep ^http过滤出以http开头的字符串。再后面的sort和uniq就一目了然了。
重点是sed 's/xx(yyy)zz/\1/'这个命令,sed中\1表示将()中的匹配到的字符串进行返回,上面命令中,yyy=http:\/\/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}。
修改配置文件
现在很多配置文件是json格式的,使用shell去修改json文件可以不需要依赖额外的json库。假设现在我们想把json文件中如下的:
{
...
"upload_period":600,
...
}
upload_period时间修改为30,可以执行如下命令:
sed -i "s/\"upload_period\"":.*$/\"upload_period\":30,/" config.json
基本函数使用
fork 函数
子进程获得父进程数据空间、堆和栈的副本,父、子进程并不共享这些存储空间部分。 另外,fork的一个特性是父进程的所有打开描述符都被复制到子进程中,父、子进程的每个相同的打开描述符共享一个文件表现。 通过下面两个例子来演示一下:
#include "apue.h"
int glob = 6;
char buf[] = "a write to stdout\n";
int main(void)
{
int var;
pid_t pid;
var = 88;
if(write(STDOUT_FILENO, buf, sizeof(buf)-1) != sizeof(buf) - 1)
err_sys("write error");
prnitf("before fork\n");
if((pid = fork()) < 0){
err_sys("fork error");
}else if(pid == 0){
glob++;
var++;
}else{
sleep(2); /*parent*/
}
printf("pid = %d, glob = %d, var = %d\n", getpid(). glob, var);
exit(0);
}
执行此程序则得到:
$./a.out a write to stdout before fork pid = 430, glob = 7, var = 89 子进程的变量值改变了 pid = 429, glob = 6, var = 88 父进程的变量值没有改变 $ ./a.out > temp.out $cat temp.out a write to stdout before fork pid = 432, glob = 7, var = 89 before fork pid = 431, glob = 6, var = 88
除了注意上面执行结果的注释部分说明了子进程复制父进程的存储空间并且子进程对变量所作的
改变并不影响父进程中的该变量的值以外,还要注意fork与I/O函数之间的交互关系。
write函数是不带缓冲的,但是,标准I/O库是带缓冲的。如果标准输出连接到终端设备,则它是行缓冲的,
否则它是全缓冲的。当以交互方式运行该程序时,只得到该printf输出的行一次,其原因是标准输出
缓冲区由换行符冲洗。但是当标准输出重定向到一个文件时,却得到printf输出两次。
其原因是,在fork之前调用了printf一次,但当调用fork时,该行数据仍在缓冲区中,然后在将父进程数据空间
复制到子进程时,该缓冲区也被复制到子进程中。当每个进程终止时,最终会冲洗其缓冲区中的副本。
exec 函数
当进程调用一种exec函数时,该进程执行的程序完全替换为新程序,而新程序则从其main函数开始执行。
因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用一个全新的程序替换了当前进程的正文、数据、堆和栈段。
exec加上v, l, e, p这4个字母的两两组合或者单独一个总共有6种不同的函数可供使用。
| 字母 | 词意 | 说明 |
| v | vector | v表示传递参数时应先构造一个指向各参数的指针数组,然后将该数组地址作为参数传递。 |
| l | list | l与上面的v是向对应的,表示要求将新程序的每个命令行参数都说明为一个单独的测试,并且这种参数表以空指针结尾。 |
| e | environment | e表示在向新程序传递环境表时,可以传递一个指向环境字符串指针数组的指针。 |
| p | path | p表示可以通过传递文件名来定位新程序文件的位置,但是是如果传递的文件名中如果包含/,则会忽略’p’的作用,将其视为路径名。否则就按PATH环境变量去搜索。 |
*值得注意的是:如果
execlp或者execvp使用PATH搜索到一个可执行文件,但是该文件不是由连接器产生的机器可执行文件,则认为该文件时应该shell脚本,于是试着调用/bin/sh,并以该filename作为shell的输入。
#include /system函数
#include <stdlib.h>
int system(const char *cmdstring);
- 如果cmdstring是一个空指针,则仅当命令处理程序可用时,system返回非0值,这一特征可以确定在一个给定的操作系统上是否支持system 函数。
- 因为system在其实现中调用了fork、exec和waitpid,因此有三种返回值: 1).如果fork失败或者waitpid返回除EINTR之外的出错,则system返回-1,而且errno中设置了错误类型。 2).如果exec失败,则其返回值如同shell执行了exit(127)一样。 3).如果3个函数都执行成功,返回值是shell的终止状态。
因为system函数内部实现是调用比较耗内存的fork函数,所以实际项目中经常出现,在内存资源紧张时调用system()出现返回-1的失败,且此时的errno对应的字符串 为”cannot allocate memory”。这个时候一种算是规避的解决办法就是通过调用vfork()自己实现system函数的功能。下面贴出代码实现:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <errno.h>
int run_cmd(const char *cmd)
{
struct sigaction ignore, saveintr, savequit;
sigset_t childmask, savemask;
pid_t pid;
int status = 0;
if(!cmd)
{
perror("cmd is NULL\n");
return 1;
}
/**
* ignore sigint and sigquit.
*/
ignore.sa_handler = SIG_IGN;
sigempteyset(&ignore.sa_mask);
ignore.sa_flags = 0;
if(sigaction(SIGINT, &ignore, &saveintr) < 0)
{
printf("sigaction SIGINT fail %d - %s\n", errno, strerror(errno));
return -1;
}
if(sigaction(SIGQUIT, &ignore, &savequit) < 0)
{
printf("sigaction SIGQUIT fail %d - %s\n", errno, strerror(errno));
return -1;
}
/**
* block sigchld.
*/
sigemptyset(&childmask);
sigaddset(&childmask, SIGCHLD);
if(sigprocmask(SIG_BLOCK, &childmask, &savemask) < 0)
{
printf("sigprocmask SIGCHLD fail %d - %s\n", errno, strerror(errno));
return -1;
}
if((pid = vfork()) < 0)
{
printf("vfork fail %d\n", (int)pid);
status = -1;
}
else if(pid == 0)
{
/**
* here comes the child
*/
sigaction(SIGINT, &saveintr, NULL);
sigaction(SIGQUIT, &savequit, NULL);
sigprocmask(SIG_SETMASKM, &savemask, NULL);
execlp("sh", "sh", "-c", cmd, (char *)0);
_exit(127);
}
else
{
/**
* here comes the parent
*/
while(waitpid(pid, &status, 0) < 0)
{
if(errno != EINTR)
{
status = -1;
printf("waitpid fail %d - %s\n", errno, strerror(errno));
break;
}
}
}
sigaction(SIGINT, &saveintr, NULL);
sigaction(SIGQUIT, &savequit, NULL);
sigprocmask(SIG_SETMASKM, &savemask, NULL);
return status;
}
exit函数
在大多数UNIX系统实现中,exit(3)是标准C库中的一个函数,而_exit(2)则是一个系统调用。 进程要么是正常终止返回退出状态(exit status),要么异常终止返回终止状态(terminatiom status)。 在任意一种情况下,该终止进程的父进程都能够使用wait或者waitpid函数取得其终止状态。
值得注意的是,在最后调用_exit时,内核将退出状态转换成终止状态。
有四个互斥的宏可用来取得进程终止的原因,它们的名字以WIF开始:
| 宏 | 说明 |
|---|---|
| WIFEXITED(status) | 若为正常终止子进程返回的状态。则为真。对于这种情况可执行WEXITSTATUS(status),取子进程传给exit、_exit或_Exit参数的低8位。 |
| WIFSIGNALED(status) | 若为异常终止子进程返回的状态,则为真。执行WTERMSIG(status)取使子进程终止的信号编号。 |
| WIFSTOPPED(status) | 若为当前暂停子进程的返回的返回状态,则为真。执行WSTOPSIG(status)取使子进程暂停的信号编号 |
| WIFCONTINUED(status) | 若在作业控制暂停后已经继续的子进程返回了状态,则为真。仅用于waitpid。 |
对于waitpid函数中pid参数的作用解释如下:
| pid值 | 说明 |
|---|---|
| -1 | 等待任一子进程。就这一方面而言,waitpid与wait等效。 |
| >0 | 等待其进程ID与pid相等的子进程。 |
| ==0 | 等待其组ID等于调用进程组ID的任一子进程。 |
| <-1 | 等待其组ID等于pid绝对值的任一子进程。 |
守护进程
编写守护进程时的基本规则:
- 首先要做的是调用umask将文件模式创建屏蔽字设置为0.
- 调用fork,然后使父进程退出。这样做实现了2点:1).如果该守护进程是由shell命令启动的 那么父进程终止使得shell认为这条命令已经执行完毕。2).子进程继承了父进程的进程组ID,但具有一个新的进程ID,这就保证了子进程不是一个进程组的组长进程。 这对于下面就要做的setsid调用是必要的前提条件。
- 调用setsid以创建一个新会话。之后该进程:1).成为新会话的首进程。2).成为一个新进程组的组长进程。c).没有控制终端。
- 将当前工作目录更改为根目录。
- 关闭不再需要的文件描述符。
- 某些守护进程打开/dev/null使其具有描述符0,1和2.
标准I/O库
打开流
下面3个函数打开一个标准I/O流。
FILE *fopen(const char *restrict pathname, const char *restrict type);
FILE *freopen(conat char *restrict pathname, const char *restrict type, FILE *restrict fp);
FILE *fdopen(int fileds, const char *type);
这三个函数的区别是: (1)fopen打开一个指定的文件。 (2)freopen在一个指定的流上打开一个指定的文件,