更新于2022-12-16
进阶
Exception-Safe Code
基础知识
C++11 Memory Model
2011年发布的C11/C++11 ISO 标准中引入了memory model的支持,从而保证无论代码运行在何种平台上,使用何种编译器,多线程下访问内存的行为都保持一套标准方法。也就是在语言层面提供了一个实现对多处理器对共享内存交互控制的抽象层,让开发者可以写出更好更安全的并发代码。
内存模型(memory model)其实是和CPU的体系架构有直接关系的,不同的CPU体系内存顺序模型是不一样的:
| architecture | memory model |
|---|---|
| x86_64 | Total Store Order |
| sparc | Total Store Order |
| ARMv8 | weakly Ordered |
| PowerPC | weakly Ordered |
| MIPS | weakly Ordered |
所谓的Total Store Order(强顺序模型)就是内存在写操作上是有一个全局的顺序的,就好像在内存上的每个store操作都必须排队,轮流按序执行,所有的行为组合只会是所有CPU内存指令的顺序交织,不会发生和顺序不一致的地方。TSO模型有利于多线程代码的编写,但对芯片实现不友好,CPU为了TSO的保证,会牺牲一些并发上的执行效率。
弱内存模型(WMO, weak memory ordring), 是把是否要求强制顺序这个要求直接交给程序员的方法,CPU不去保证这个顺序模型,而是提供了内存屏障的指令让程序员显示的强化这个可进性。 ARMv8,PowerPC和MIPS等体系结构都是弱内存模型, 每种弱内存模型的体系架构都有自己的内存屏障指令,语义也不完全相同。 弱内存模型下,硬件实现起来相对简单,处理器执行的效率也高, 只要没有遇到显式的屏障指令,CPU可以对局部指令进行reorder以提高执行效率。
c++11使用memory order来描述memory model, 提供了6种memory order:
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
每种memory order的规则如下:
| 枚举值 | 定义规则 |
|---|---|
| memory_order_relaxed | 不对执行顺序做任何保证 |
| memory_order_consume | 本线程中,所有后续的有关原子操作,必须在本条原子操作之后执行 |
| memory_order_acquire | 本线程中,所有后续的读操作必须在本条原子操作完成后执行 |
| memory_order_release | 本线程中,所有之前的写操作完成后才能执行本条原子操作 |
| memory_order_acq_rel | memory_order_acquire && memory_order_release |
| memory_order_seq_cst | 全部存取都按顺序执行 == TSO |
memory_order_relaxed
Relaxed ordering仅仅保证load()和store()是原子的,不提供任何跨线程下的同步。
std::atomic<int> x = 0; //global variable
std::atmoic<int> y = 0; //global variable
Tread_1:
{
r1 = y.load(memory_order_relaxed); //A
x.store(r1, memory_order_relaxed); //B
}
Tread_2:
{
r2 = x.load(memory_order_relaxed); //C
y.store(999, memory_order_relaxed);//D
}
在memory_order_relaxed模式下,CPU在执行的时候允许局部指令reorder,所以可能出现的执行顺序是D->A->B->C, 这样的话就出现r1==r2==999
memory_order_consume/release
consume要搭配release一起使用。很多时候,线程间只想针对有依赖关系的操作进行同步,除此之外线程中其他操作顺序不关心,这个时候就适合用consume来完成这个操作,比如:
b = *a;
c = *b;
具体实例代码如下:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string *> ptr;
int data;
void producer()
{
std::string *p = new std::string("hello"); //A
data = 999;
//在下面这条语句执行前,保证A语句必须执行完成
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string *p2;
while(!(p2 = ptr.load(std::memory_order_consume)));
assert(*p2 == "hello"); //never filres
assert(data == 999); //may or may not fire
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
}
上面assert(*p2 == “Hello”)永远不会失败,但assert(data == 42)可能会。 原因是:
- p2和ptr直接有依赖关系,但data和ptr没有直接依赖关系
- 尽管producer线程中data赋值在ptr.store()之前,consumer线程看到的data的值还是不确定的
memory_order_acquire/relase
acquire和release也必须放到一起使用,release和acquire构成了synchronize-with关系,也就是同步关系。在这个关系下: 线程A中所有发生在release x之前的写操作,对线程B的acquire x之后的任何操作都可见。
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
#include <iostream>
std::atomic<bool> ready{ false };
int data = 0;
std::atomic<int> var = {0};
void sender()
{
data = 999;
var.store(100, std::memory_order_relaxed);
//所有之前的`写`操作完成后才能执行本条原子操作
ready.store(true, std::memory_order_release); //C
}
void receiver()
{
//所有后续的`读`操作必须在本条原子操作完成后执行
while(!ready.load(std::memory_order_acquire)); //D
assert(data == 999); //never fail
assert(var == 100); //never fail
}
int main()
{
std::thread t1(sender);
std::thread t2(receiver);
t1.join();
t2.join();
}
上面的例子中:
- sender和receiver在C和D处发生了同步
- 线程sender中C之前的所有读写对线程receiver都是可见的, 对比上面的cosume/release的例子可见,release/acquire组合同步性更强.
memory_order_acq_rel
#include <thread>
#include <atomic>
#include <cassert>
#include <vector>
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1()
{
data.push_back(42);
flag.store(1, std::memory_order_release);
}
void thread_2()
{
int expected=1;
while (!flag.compare_exchange_strong(expected, 2, std::memory_order_acq_rel)) {
expected = 1;
}
}
void thread_3()
{
while (flag.load(std::memory_order_acquire) < 2)
;
assert(data.at(0) == 42); // will never fire
}
int main()
{
std::thread a(thread_1);
std::thread b(thread_2);
std::thread c(thread_3);
a.join(); b.join(); c.join();
}
memory_order_seq_cst
seq_cst表示顺序一致性内存模型,在这个模型约束下不仅同一个线程内的执行结果是和程序顺序一致的, 每个线程间互相看到的执行结果和程序顺序也保持顺序一致。 显然,seq_cst的约束是最强的,这意味着要牺牲性能为代价.
const修饰类成员函数
把一个成员函数声明为const可以保证成员函数不修改类的数据成员,但是,如果该类含有指针,那么在const成员函数中就能修改所指的对象,因为编译器检测不到 这种错误。
#include <cstring>
class Text{
public:
void bad(const string &parm) const;
private:
char *_text;
};
void Text::bad(const string &parm) const
{
_text = parm.c_str(); //错误:不能修改_text
for(int ix = 0; ix < parm.size(); ++ix)
_text[ix] = parm[ix]; //不好的风格,但是ok的
}
这个问题可以联想到c语音中const的使用:
const char *p = "saiyn";
const char * const q = "love bq";
p = "it's ok";
*p = 'w'; // 错误,不能修改p指向内存块的内容
q = "it's wrong"; //错误,不能修改q的地址
*q = 'w'; //错误
上面代码中,对于变量p, 它本身的地址是可以修改的,也就是说可以修改p指向其他内存地址;而对于变量q,它本身的地址和它指向的内存块都不可以被修改。 可见,c++中的这个const修饰效果和上面第二行地二个const修饰效果是一样的。
const成员函数的另外一个特性是,它可以被相同参数表的非const成员函数重载:
class screen{
public:
char get(int x, int y);
char get(int x, int y) const;
...
};
在这种情况下,类对象的常量性决定了调用哪个函数:
int main(){
const screen cs;
screen s;
char ch = cs.get(0,0); // 调用const成员
ch = s.get(0,0); //调用非const成员
}
特性
Rvalue Reference
c++11中引入了右值的概念,所谓右值,最简单的理解就是凡是无法使用&取得其地址的都是rvalue,比如下面代码:
int a = 1;
我们可以通过&a取得变量a的地址,而无法通过&1取得常量的地址,所以,这里的a就是左值(lvalue),1就是右值(rvalue)。另外一个常见的右值,也是
c++11引入右值概念主要针对的,比如如下代码:
int getData()
{
return 9;
}
getData()就是一个右值。相对于
int & lref = a;
这样定义一个左值引用,我们可以使用&&定义一个右值引用
int && rref = getData();
下面通过实例代码来解析,c++11中引入右值概念主要解决的Temporary Objects问题。
class Container{
int *m_data;
public:
Container(){
m_data = new int[20];
}
~Container(){
if(m_data){
delete[] m_data;
m_data = NULL;
}
}
Container(const Container &obj){
m_data = new int[20];
for(int i = 0; i < 20; i++){
m_data[i] = obj.m_data[i];
}
}
};
上面Container类的default constructor和copy constructor都需要调用new在堆上分配内存
Container getContainer()
{
Container obj;
return obj;
}
int main()
{
std::vector<Container> vec;
vec.push_back(getContainer());
return 0;
}
在上面代码的执行中,我们发现,为了向vector中放入一个container对象,我们需要
-
在getContainer()函数中调用default constructor。
-
在调用push_back时,需要调用copy constructor。
这样我们在堆上创建了两个对象,并且最后只用到了一个,另外一个临时对象(Temporary Object)的创建很浪费。为此,右值特性派上用场了。原理就是 使用Rvalue Reference 和 move constructor。
class Container{
int *m_data;
public:
Container(){
m_data = new int[20];
}
~Container(){
if(m_data){
delete[] m_data;
m_data = NULL;
}
}
Container(const Container &obj){
m_data = new int[20];
for(int i = 0; i < 20; i++){
m_data[i] = obj.m_data[i];
}
}
Contailer(Contailer && obj)
{
//just copy the pointer
m_data = obj.m_data;
obj.m_data = NULL;
}
};
这样当我们只需vec.push_back(getContainer())时,move constructor就会被调用,避免了创建临时对象以及内存拷贝。
std::move
std::move的作用是将一个左值引用强制转换为右值引用,比如
Container a;
Container b = a; //调用copy constructor
Container c = std::move(a); //调用move constructor
但是这时,需要思考的一个问题时,强制使用move constructor后,会不会导致改变a对象内部数据时同时也就改掉了c对象中的数据?
std::bind
std::bind是一个标准的函数对象,充当功能适配器(Functioanl Adaptor)。
应用实例
使用std::bind的功能可以实现在基类中动态绑定派生类定义的callback函数,这个功能在c++98中是无法实现的。
#include <iostream>
class base {
private:
std::function<void (int)> action;
protected:
virtual void onDataBaseReady(int i) { std::cout << i << std::endl; }
public:
void call() {
action(10);
}
base() {
action = std::bind(&base::onDataBaseReady, this, _1);
}
};
class child : public base {
protected:
virtual void onDataBaseReady(int i) { std::cout << i+10 << std::endl; }
};
int main()
{
static child c;
c.call();
std::cin.get();
return 0;
}
onDataBaseReady是我们可以在不同派生类定义的不同的函数,在基类中通过action = std::bind(&base::onDataBaseReady, this, _1),绑定了
派生类中定义的函数,乍一看,我们绑定的回调函数好像是base::onDataBaseReady,那为什么最终会绑定到派生类的函数内。这是因为我们通过&base::onDataBaseReady
传递的是基类虚函数的指针,而我们知道,在通过指针或者引用访问虚函数时,会发生override的,所以最终会调用到我们定义派生类定义的函数。
lambda表达式
在C++ 11中,lambda表达式是一种在被调用的位置或作为参数传递给函数的位置定义匿名函数对象的简便方法。
下图显示了lambda的组成部分:
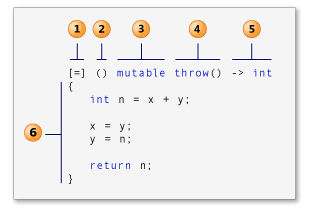
-
capture子句,在c++规范中也称为lambad引导。
-
参数列表(可选)。
-
可变规范(可选)。
-
异常规范(可选)。
-
尾随返回类型(可选)。
-
lambda主体。